The complexity of your data landscape grows with each data source, each set of business requirements, each process change, and each new regulation. Finding the most suitable ETL process for your business can make the difference between working on your data pipeline or making your data pipeline work for you.
The best approach takes into consideration your data sources, your data warehouse, and your business requirements.
How ETL works
ETL is a three-step process: extract data from databases or other data sources, transform the data in various ways, and load that data into a destination.
In the AWS environment, data sources include S3, Aurora, Relational Database Service (RDS), DynamoDB, and EC2. Amazon Redshift is a data warehouse and S3 can be used as a data lake.
Cloud-native data warehouses like Redshift can scale elastically to handle just about any processing load, which enables data engineers to run transformations on data after loading. This changes the data pipeline process for cloud data warehouses from ETL to ETL Training
DIY data pipeline — big challenge, bad business
ETL is part of the process of replicating data from one system to another — a process with many steps. For instance, you first have to identify all of your data sources. Then, unless you plan to replicate all of your data on a regular basis, you need to identify when source data has changed.
You also need to select a data warehouse destination that provides an architecture that’s appropriate for the types of data analysis you plan to run, fits within your budget, and is compatible with your software ecosystem.
You then can task a data engineer on your internal team with manually coding a reusable data pipeline. However, writing ETL code is not simple — among other things, data engineers need to: ETL Testing Training
Learn how to use the data sources’ APIs
Write the logic for the extraction process
Code in security, logging, and alerting capabilities
Test their work
Review pipeline performance regularly
Repeat many of these steps as they maintain the code over time
Given all that, many organizations choose to avoid manually coding data pipelines. As Jeff Magnusson, vice president of Stitch Fix, says, “Engineers should not write ETL. For the love of everything sacred and holy in the profession, this should not be a dedicated or specialized role. There is nothing more soul sucking than writing, maintaining, modifying, and supporting ETL to produce data that you yourself never get to use or consume.”
Fortunately, there’s a smart alternative to writing and maintaining your own ETL code. If you want to follow Magnusson’s advice, you can turn to a SaaS service to handle ETL tasks. In the AWS world, AWS Glue can handle ETL jobs, or you can consider a third-party service like Stitch.
Should you stick with AWS Glue for ETL?
AWS Glue is a managed ETL service that you control from the AWS Management Console. Glue may be a good choice if you’re moving data from an Amazon data source to an Amazon data warehouse.
Glue’s ETL process is similar to that of a manually coded data pipeline:
Set up a schedule or identify events to trigger an ETL job.
Extract data from AWS data sources.
Transform data based on code generated automatically by AWS Glue.
Load data into either Redshift or S3.
Write metadata pertaining to the ETL job into the AWS Glue Data Catalog.
However, Glue supports only services running on AWS:
Amazon Aurora
Amazon RDS for MySQL
Amazon RDS for Oracle
Amazon RDS for PostgreSQL
Amazon RDS for SQL Server
Amazon Redshift
Amazon S3
MySQL in Amazon VPC running on EC2
Oracle in Amazon VPC running on EC2
Microsoft SQL Server in Amazon VPC running on EC2
PostgreSQL in Amazon VPC running on EC2
If you need to include other sources in your ETL plan, a third-party ETL tool is a better choice. ETL Testing Certification
Using a third-party AWS ETL tool
Third-party AWS ETL tools often have advantages over AWS Glue and internal pipelines. They support integrations with non-AWS data sources through graphical interfaces, and offer attractive pricing models.
How do you pick the most suitable ETL tool for your business? Start by asking questions specific to your requirements:
Does an ETL tool integrate with every data source you use today?
Will it integrate with new data sources — even those that are less popular or custom-built? To be prepared to take advantage of new data sources, consider an extensible solution like Stitch, whose Singer open source framework lets you integrate new data sources.
What kind of reliability do you need? It’s tough to beat the fault tolerance of a cloud-native service.
What are your requirements for performance and scalability?
Does it meet your security requirements? Do you need to meet HIPAA, PCI, or GDPR compliance requirements?
Pricing models vary among ETL services. Does the solution charge by the hour, number of data sources, or a combination of factors? Make sure the solution is priced in a way that makes sense for your business’s usage.
What replication scheduling options are available and how is replication handled? What happens if a replication job is still running when the next is supposed to start? Can you specify a start time to establish a predictable schedule?
What types of support are available? Is quality documentation available online? Is in-app support available? Is there an online community to share knowledge with?
Stitch any data source to AWS
Stitch supports Amazon Redshift and S3 destinations and more than 90 data sources, and provides businesses with the power to replicate data easily and cost-effectively while maintaining SOC 2, HIPAA, and GDPR compliance. As a cloud-first, extensible platform, Stitch lets you reliably scale your ecosystem and integrate with new data sources — all while providing the support and resources to answer any of your questions.
Welcome to the Azure DevOps Services REST API Reference.
Representational State Transfer (REST) APIs are service endpoints that support sets of HTTP operations (methods), which provide create, retrieve, update, or delete access to the service’s resources. This article walks you through:
The basic components of a REST API request/response pair.
Overviews of creating and sending a REST request, and handling the response.
Most REST APIs are accessible through our client libraries, which can be used to greatly simplify your client code. For more details DevOps Online Course
Components of a REST API request/response pair
A REST API request/response pair can be separated into five components:
The request URI, in the following form: VERB https://{instance}[/{team-project}]/_apis[/{area}]/{resource}?api-version={version}
instance: The Azure DevOps Services organization or TFS server you’re sending the request to. They are structured as follows:
TFS:{server:port}/tfs/{collection} (the default port is 8080, and the value for collection should be DefaultCollection but can be any collection)
resource path: The resource path is as follows: _apis/{area}/{resource}. For example _apis/wit/workitems.
api-version: Every API request should include an api-version to avoid having your app or service break as APIs evolve. api-versions are in the following format: {major}.{minor}[-{stage}[.{resource-version}]], for example:
api-version=1.0
api-version=1.2-preview
api-version=2.0-preview.1
Note: area and team-project are optional, depending on the API request. Check out the TFS to REST API version mapping matrix below to find which REST API versions apply to your version of TFS.
HTTP request message header fields:
A required HTTP method (also known as an operation or verb), which tells the service what type of operation you are requesting. Azure REST APIs support GET, HEAD, PUT, POST, and PATCH methods.
Optional additional header fields, as required by the specified URI and HTTP method. For example, an Authorization header that provides a bearer token containing client authorization information for the request.
Optional HTTP request message body fields, to support the URI and HTTP operation. For example, POST operations contain MIME-encoded objects that are passed as complex parameters.
For POST or PUT operations, the MIME-encoding type for the body should be specified in the Content-type request header as well. Some services require you to use a specific MIME type, such as application/json.
HTTP response message header fields:
An HTTP status code, ranging from 2xx success codes to 4xx or 5xx error codes. Alternatively, a service-defined status code may be returned, as indicated in the API documentation.
Optional additional header fields, as required to support the request’s response, such as a Content-type response header.
Optional HTTP response message body fields:
MIME-encoded response objects may be returned in the HTTP response body, such as a response from a GET method that is returning data. Typically, these objects are returned in a structured format such as JSON or XML, as indicated by the Content-type response header. For example, when you request an access token from Azure AD, it will be returned in the response body as the access_token element, one of several name/value paired objects in a data collection. In this example, a response header of Content-Type: application/json is also included. Learn more from Learn DevOps Online
Create the request
Authenticate
There are many ways to authenticate your application or service with Azure DevOps Services or TFS.
Assemble the request
Azure DevOps Services
For Azure DevOps Services, instance is dev.azure.com/{organization}, so the pattern looks like this:
If you wish to provide the personal access token through an HTTP header, you must first convert it to a Base64 string (the following example shows how to convert to Base64 using C#). (Certain tools like Postman applies a Base64 encoding by default. If you are trying the API via such tools, Base64 encoding of the PAT is not required) The resulting string can then be provided as an HTTP header in the format:
Authorization: Basic BASE64PATSTRING
Here it is in C# using the HttpClient class.
public static async void GetProjects()
{
try
{
var personalaccesstoken = "PAT_FROM_WEBSITE";
using (HttpClient client = new HttpClient())
{
client.DefaultRequestHeaders.Accept.Add(
new System.Net.Http.Headers.MediaTypeWithQualityHeaderValue("application/json"));
client.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Basic",
Convert.ToBase64String(
System.Text.ASCIIEncoding.ASCII.GetBytes(
string.Format("{0}:{1}", "", personalaccesstoken))));
using (HttpResponseMessage response = await client.GetAsync(
"https://dev.azure.com/{organization}/_apis/projects"))
{
response.EnsureSuccessStatusCode();
string responseBody = await response.Content.ReadAsStringAsync();
Console.WriteLine(responseBody);
}
}
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
}
}
Most samples on this site use Personal Access Tokens as they’re a compact example for authenticating with the service. However, there are a variety of authentication mechanisms available for Azure DevOps Services including ADAL, OAuth and Session Tokens. Refer to the Authentication section for guidance on which one is best suited for your scenario.
TFS
For TFS, instance is {server:port}/tfs/{collection} and by default the port is 8080. The default collection is DefaultCollection, but can be any collection.
Here’s how to get a list of team projects from TFS using the default port and collection.
java.util.ConcurrentModificationException is a very common exception when working with Java collection classes. Java Collection classes are fail-fast, which means if the Collection will be changed while some thread is traversing over it using iterator, the iterator.next() will throw ConcurrentModificationException.
Concurrent modification exception can come in case of multithreaded as well as a single threaded java programming environment.
public class ConcurrentModificationException
extends RuntimeException
This exception may be thrown by methods that have detected concurrent modification of an object when such modification is not permissible.
For example, it is not generally permissible for one thread to modify a Collection while another thread is iterating over it. In general, the results of the iteration are undefined under these circumstances. For more info Java Online Classes
Some Iterator implementations (including those of all the general purpose collection implementations provided by the JRE) may choose to throw this exception if this behavior is detected.
Iterators that do this are known as fail-fast iterators, as they fail quickly and cleanly, rather that risking arbitrary, non-deterministic behavior at an undetermined time in the future.
This exception may be thrown by methods that have detected concurrent modification of an object when such modification is not permissible.
For example, it is not generally permissible for one thread to modify a Collection while another thread is iterating over it. In general, the results of the iteration are undefined under these circumstances.
Some Iterator implementations (including those of all the general purpose collection implementations provided by the JRE) may choose to throw this exception if this behavior is detected.
Iterators that do this are known as fail-fast iterators, as they fail quickly and cleanly, rather that risking arbitrary, non-deterministic behavior at an undetermined time in the future. Get additional info from Core Java Online Training
To Avoid ConcurrentModificationException in multi-threaded environment
You can convert the list to an array and then iterate on the array. This approach works well for small or medium size list but if the list is large then it will affect the performance a lot.
You can lock the list while iterating by putting it in a synchronized block. This approach is not recommended because it will cease the benefits of multithreading.
If you are using JDK1.5 or higher then you can use ConcurrentHashMap and CopyOnWriteArrayList classes. This is the recommended approach to avoid concurrent modification exception.
To Avoid ConcurrentModificationException in single-threaded environment
You can use the iterator remove() function to remove the object from underlying collection object. But in this case, you can remove the same object and not any other object from the list.
Iterator’s remove method
In a single-threaded environment, use the iterator’s remove method, in order to concurrently iterate over a collection and remove things from it. For example:
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class Example_v4 {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
// Insert some sample values.
list.add("Value1");
list.add("Value2");
list.add("Value3");
// Get an iterator.
Iterator<String> ite = list.iterator();
/* Remove the second value of the list, while iterating over its elements,
* using the iterator's remove method. */
while(ite.hasNext()) {
String value = ite.next();
if(value.equals("Value2"))
ite.remove();
else
System.out.println(value);
}
}
}
Synchronized Collections
In addition to their default implementations, Java provides a synchronized implementation of a Map, a List, a Set, a Collection, etc. through the Collections class.
Moreover, Java provides the CopyOnWriteArrayList class, in which all mutative operations are implemented by making a fresh copy of the underlying array. Finally, Java also provides the ConcurrentHashMap class, which offers full concurrency of retrievals and adjustable expected concurrency for updates.
All referenced implementations are thread safe. However, the usage of such data structures may also reduce the performance of your application, as thread synchronization spends CPU cycles.
To conclude, all aforementioned methods aim to eliminate the ConcurrentModificationException. However, in a multi-threaded environment this elimination usually comes with the cost of thread synchronization.
In any case, each application has its own specifications and requirements and thus, a meticulous design and implementation are very important in order for such exceptions to be eliminated.
Example:
import java.awt.List;
import java.util.*;
public class concurrentmodificationexception {
public static void main(String[] args) {
HashMap<Integer, Integer> map = new HashMap<>();
map.put(1, 1);
map.put(2, 2);
map.put(3,3);
Iterator<Integer> it = map.keySet().iterator();
while(it.hasNext()) {
Integer key = it.next();
System.out.println("Map Value:" + map.get(key));
if (key.equals(2)) {
map.put(1, 4);
}
}
}
}
Constructors of ConcurrentModificationException
There are 4 types of constructors of ConcurrentModificationException –
public ConcurrentModificationException()- This creates a ConcurrentModificationException with no parameters.
public ConcurrentModificationException(String message) This creates a ConcurrentModificationException with a detailed message specifying the Exception.
public ConcurrentModificationException(Throwable cause) This creates a ConcurrentModificationException with a cause and a message which is (cause==null?null:cause.toString()). The cause is later retrieved by the Throwable.getCause().
public ConcurrentModificationException(String message, Throwable cause) This creates a ConcurrentModificationException with a detailed message and a cause. (cause==null?null:cause.toString()). The message is later retrieved by Throwable.getMessage() and cause is later retrieved by Throwable.getCause().
Some of the all-time best books for Java programmers ranging from core Java to best practices to unit testing to spring framework.
If you are a Java programmer and are wondering what to read to improve your knowledge of Java or become a better Java developer, then you have come to the right place.
In this article, I am going to share some of the best Java books ever written. These books have withstood the test of time, becoming more and more relevant as the years go by.
It doesn’t matter if you read them in 2018 or plan on reading them in 2019, you will always have a lot to learn and that’s why I think they are the greatest Java books of all time.
Personally, I am a big fan of reading books. I have hundreds of books and eBooks in my library. When I was a kid, I read a lot of comics, including Super Commando Dhruv, who was one of my favorite characters because of the scientific theme in his stories and how he usually defeats his more powerful enemies without any superpower and just by using his intelligence, acumen, and simple knowledge of scientific facts.
My passion for books continued when I became a programmer. The first Java book I read, apart from textbooks in college, was Head First Design Pattern. This book completely changed my knowledge of Java and understanding of object-oriented programming. For more info Core Java Online Training
Until then, I didn’t understand the real use of the interface. To me, they look useless, because you can’t write code to do anything there. But, after reading the book, I realized how awesome they are in terms of reducing the coupling between different parts of your program.
From that point, I have read many programming books, mostly related to Java. Today, I am going to share the 10 best Java books that every Java developer should read. Even if some knowledge is out-dated, most of the stuff you learn will help build upon your knowledge and a lifetime career.
Top 10 Java Books of All-Time
Without further ado, here is my list of some of the most popular and important books for Java programmers.
If you have been doing Java programming for 2 to 3 years, then it’s a good chance that you have read these books already. But, if you haven’t, now is the best time to read them.
I am 100% sure that You will not regret investing your time and money on these books because what you will learn is worth much more than and last for years to come.
Effective Java:
There should not be any surprise here. Effective Java by Joshua Bloch is hands down best Java book ever. This is a definite must-read book for Java programmers of any experience level. You will learn so much about Java and its API then you could imagine.
The fact that Joshua Bloch himself is the author of several key Java classes and API, like java.lang and Java Collection framework, is enough reason to read this book. Along with that, his writing style is also fantastic.
You can read this book on a beach, while traveling, or just at your desk. It’s awesome. There is no doubt that you would emerge as better Java Training programmer after reading this book.
And the best thing is that a new edition of Effective Java is available now, which covers Java 7, 8, and 9. There cannot be a better time to read this book.
Clean Code
Another timeless classic for Java programmers is Clean Code. As the title suggests, it teaches you to write better code, which is such a difficult thing to learn.
To be honest, it’s easy to learn Java, but difficult to write better Java code which uses strong OOP principles and that’s where this book helps.
Similar to Joshua Bloch, Robert C. Martin, also known as Uncle Bob, is an excellent author and shares a lot of his experience as a software developer, teaching you various programming techniques and practices that help a lot in your day-to-day job as a programmer.
If you follow Clean Code, there is also a course on Pluarlsight called Clean Code: Writing Code for Humans By Cory House which effectively complements this book.
Btw, you would need a Pluralsight membership to get access this course, which cost around $29 per month or $299 annually (14% discount).
If you don’t have Pluralsight membership, I encourage you to get one because it allows you to access their 5000+ online courses on all latest topics like front-end and back-end development, machine learning etc.
It also include interactive quizzes, exercises, and latest certification material . It’s more like Netflix for Software Developers and Since learning is an important part of our job, Plurlasight membership is a great way to stay ahead of your competition.
They also provide a 10-day free trial without any commitment, which is a great way to not just access this course for free but also to check the quality of courses before joining Pluralsight. Get your career into new heights with Java Online Training
Java Concurrency in Practice
Multithreading and concurrency is an essential part of Java programming. There is no better book than Brian Goetz’s Java Concurrency in Practice to learn and master this tricky topic.
Even though the book only covers Java 5, it’s still relevant and must-read books for any serious Java developer.
Some of you may find that some of the sections are a bit difficult to understand, especially sections 3.5.1 through 3.5.6, And if that’s the case, I suggest you go through the Extreme Java — Concurrency Performance course by Dr. Heinz Kabutz. This will help you to better digest and comprehend those topics.
Head First Design Patterns
Good knowledge of OOP and design patterns are important for writing any Java application. Head First Design Patterns is the best book for learning to do that.
As I have said before, this was one of the first books I ever read on Java, apart from textbooks. After reading this book, I was very impressed.
This is the book that taught me why Composition is better than Inheritance and how you can change runtime behavior of a class without touching the already tried and tested code.
You might think that it’s just another old book, but you don’t need to worry, an updated copy that covers Java SE 8 was released a couple of years ago.
If you are serious about learning design patterns in Java, this is the book you should read!
The Design Pattern Library course on Pluralsight is also a nice resource to get yourself familiar with essential design patterns in Java and object-oriented programming. You can follow that course along with this book to get the best of both the worlds.
Spring in Action
Sorry, but I have to include one Spring book, Spring in Action, in this list of classic books for Java programmers. Spring is the most popular Java framework ever and this is the best book to learn about the Spring framework, but — to be honest — this book is much more than a Spring book.
After reading the 4th Edition of this book, I realized so much about Java and writing better code that I can’t begin to explain.
The books take a topic, e.g. JDBC, and explain where JDK went wrong and how Spring corrects that mistake, e.g. SQLException, a one-size-fits-all exception that says something is wrong but not exactly what is wrong or how to deal with that.
Like Josuha Bloch and Uncle Bob, Craig Walls is another great author and you will learn much more than just Spring by reading this book.
Great news is that now the 5th Edition of Spring in Action is also available, one of the books in my reading list. For programming skills Core Java Online Course
Btw, if your goal is to learn Spring, I also suggest you join a great online course like Spring Framework 5: Beginner to Guru along with this book. You will learn quickly and better than many developers, who tries to learn by self.
Test Driven:
Automation testing is an important skill. For developers, it all starts with unit testing. Java has been blessed to have the JUnit from the start, but just knowing the library doesn’t make you a professional programmer who can write tests.
It takes much more than knowing a unit testing library, like JUnit or Mockito, and that’s where this book helps. If you are serious about code quality and writing unit, integration, and automation test, Test Driven is the book to read in 2018.
If we talk about libraries, JUnit and Mockito are must for any Java developers. If you are not familiar with them, I suggest you go through this JUnit and Mockito Crash Course along with the above book to master the art of unit testing in Java.
The Definitive Guide to Java Performance
Another aspect of becoming a better Java developer is knowing about JVM, Garbage collection, and performance tuning.
Though there have been several good books on this topic, e.g. Java Performance by Binu John and Charlie Hunt, The Definitive Guide of Java Performance by Scott Oaks is my favorite.
Even though it only covers until JDK 7, you will learn a lot about performance tuning and JVM in general, which totally justifies the time and money you will spend on this book.
Head First Java
How many of you started learning Java by reading this book? Well, I did. Just after I came to know about Head First Design Pattern, I also found this book, Head First Java, and I really enjoyed reading it. I learned a lot of Java concepts and many of my misconceptions were also corrected.
Though many feel this is an out-of-date book, I still feel its a great book for anyone just starting with Java because of its unique style and content.
You can easily learn about Java 8, Java 9, and Java 10 changes on other versions once you know Java by reading this book.
Btw, If you like online courses and looking for some of the best Java courses to start your journey then The Java MasterClass on Udemy is simply the most up-to-date and the best course to start with.
Head First Object-Oriented Analysis and Design
Here is another “Head First” book in the list of the greatest Java books. Yup, they are simply awesome.
Head First Object-Oriented Analysis and Design form a trilogy of the “Head First” books for Java programmers, i.e. Head First Java, Head First Design Patterns, and Head First OOAD.
It actually complements Head First Design Patterns by explaining the techniques of object-oriented programming and design.
The most important technique that I learned from this book was coding for interfaces and how to encapsulate what changes. This book simply changed how I write Java code.
If you like courses, SOLID Principles of Object-Oriented Design by Steve Smith on Pluralsight is great and you can follow that along this book for better understanding of object-oriented design principles.
Java: A Beginner’s Guide
If you ever need a comprehensive Java book, this should be it. Even though the title says Java: A Beginner’s Guide, it’s one of the most complete books for learning Java.
Sir Herbert Schildt has also done a commendable job in keeping the book up-to-date, e.g. the 7th Edition of this book now covers Java 9.
Though, I don’t know how he is going to keep this book up-to-date going forward, since Java’s new 6-month release cycle which started with Java 10.
Between, they have released a supplement to cover JDK 10 new features. I think that would be the way going forward.
There you go! These are some of the best books for Java programmers. If you are a passionate Java programmer, there is a good chance that you have already read most of these books.
To get in-depth knowledge, enroll for a free live demo on Java Online Course
There are not many technologies that can brag about staying relevant for more than 20 years. But this year, Java was voted the 3rd most popular technology, eclipsed only by undisputed leaders JavaScript, HTML, CSS, and SQL.
While it’s 18th on the list of most loved in the same StackOverflow survey, it’s also way down the list in its most-dreaded ranking.
Today we unravel the many successes and challenges of Java — the time-honored technology with the iconic steaming cup-of-coffee logo, a language near and dear to many programmers today.
What is Java Programming: The History and Impact
Java is a general-purpose programming language that follows the object-oriented programming paradigm and the Write Once Run Anywhere approach. Java is used for desktop, web, mobile, and enterprise applications. You can out find more about it here:
Java is not only a language but an ecosystem of tools covering almost everything you may need for Java development. This includes:
Java Development Kit (JDK) — with that and a standard Notebook app you can write and run/compile Java code
Java Runtime Environment (JRE) — software distribution tool containing a stand-alone Java Virtual Machine, the Java standard library (Java Class Library), and a configuration tool
Integrated Development Environment (IDE) — tools that help you run, edit, and compile your code. IntelliJ IDEA, Eclipse, and NetBeans are the most popular ones
Java can be found anywhere you look. It’s a primary language for Android development. You will find it in web applications, governmental websites, and big data technologies such as Hadoop and Apache Storm. For more info Java Online Course
And it’s also a classic choice for scientific projects, especially natural language processing. Java was dominating mobile even in pre-smartphone days — first mobile games in the early 2000s were mostly made in Java.
So, it’s fair to say that Java, thanks to its long history, has earned its place in the Programming Hall of Fame. TIOBE index, one of the most reputable programming rankings in the world, uses search engine results for calculation.
Despite the growing popularity of Go and Python, Java has remained at the top of the list for more than a decade.
It all started in early 1990s, when the Sun Microsystems team began developing a better version of C++ — easily portable, novice-friendly, and enabled with automated memory management.
The research resulted in the creation of an altogether new language, and the name was picked from dozens of others yelled out in the meeting room. Today, the logo of a steaming coffee cup is the silent, universally recognizable symbol of programming.
And it’s no longer clear what came first — the programmers’ obsession with caffeine or associations with java, synonymous with coffee.
These are just some of the changes Java introduced to the programming world:
Flexibility. Java proved that C’s procedural, manually-allocated, and platform-dependent code wasn’t the be-all and end-all. Thanks to Java, more people started adopting object-oriented programming, a commonly-accepted practice today.
Applets. In the years before JavaScript, Java introduced applets, small web programs that provided interactive elements, especially useful for visualization and teaching.
Although they were never used for anything more than simple animations, it’s what captured the attention of many programmers and paved the road for the development of HTML5, Flash, and of course JavaScript. Learn more skills from Core Java Online Course
Test-driven development. With Java, TDD was no longer an experimental practice, but the standard way to develop software. The introduction of JUnit in 2000 is considered one of Java’s biggest contributions.
Benefits of programming in Java
Though no longer the only officially supported language for Android development and, of course, far from the only choice for web programming, Java keeps pace with the alternatives.
And since that’s not only thanks to its respectable age, let’s explore what advantages Java has to offer.
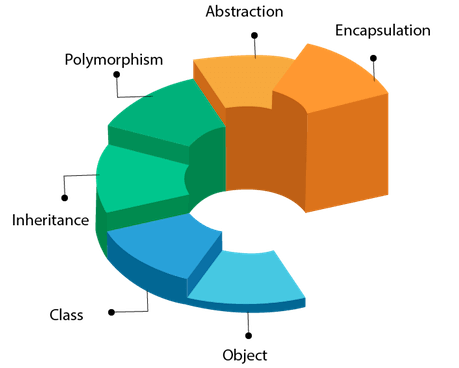
Object-oriented programming
Java embraces object-oriented programming (OOP) — a coding concept in which you not only define the type of data and its structure, but also the set of functions applied to it. This way, your data structure becomes an object that can now be manipulated to create relationships between different objects.
In contrast to another approach — procedural programming — where you have to follow a sequence of instructions using variables and functions, OOP allows you to group these variables and functions by context thus labeling them and referring to functions in the context of each specific object.Why is OOP an advantage?
You can easily reuse objects in other programs
It prevents errors by having objects hide some information that shouldn’t be easily accessed
It makes programs more organized and pre-planned, even the bigger ones
It offers simple maintenance and legacy code modernization
High-level language with simple syntax and a mild learning curve
Java is a high-level language, meaning that it closely resembles human language. In contrast to low-level languages that resemble machine code, high-level languages have to be converted using compilers or interpreters. This simplifies development, making a language easier to write, read, and maintain.
Java derived its syntax (set of rules and structure used by programmers) from C++, which is why you will notice that it closely resembles the C code. However, it’s much simpler, allowing beginners to learn the technology faster and code more effectively to achieve specific results. For programming skills Core Java Online Training
Java may not be as beginner-friendly as Python, but any developer with a basic understanding of frameworks, packages, classes, and objects can grasp it pretty soon.
It’s straightforward, strongly-typed, and has very strict expectations that soon help guide your thinking in the right direction.
Besides, tons of free online tutorials and courses, won’t keep a novice helpless.
Standard for enterprise computing
Enterprise applications are Java’s greatest asset. It started back in the 90s when organizations began looking for robust programming tools that weren’t C. Java supports a plethora of libraries — building blocks of any enterprise system — that help developers create any function a company may need.
The vast talent pool also helps — Java is the language used for introduction to computer programming in most schools and universities. Besides, its integration capabilities are impressive as most of the hosting providers support Java.
Last but not least, Java is comparatively cheap to maintain since you don’t have to depend on a specific hardware infrastructure and can run your servers on any type of machine you may have.
Shortage of security risks
You may encounter the notion that Java is a secure language but that’s not entirely true. The language itself doesn’t protect you from vulnerabilities, but some of its features can save you from common security flaws. First, compared to C, Java doesn’t have pointers.
A pointer is an object that stores the memory address of another value that can cause unauthorized access to memory.
Second, it has a Security Manager, a security policy created for each application where you can specify access rules.
This allows you to run Java applications in a “sandbox,” eliminating risks of harm.
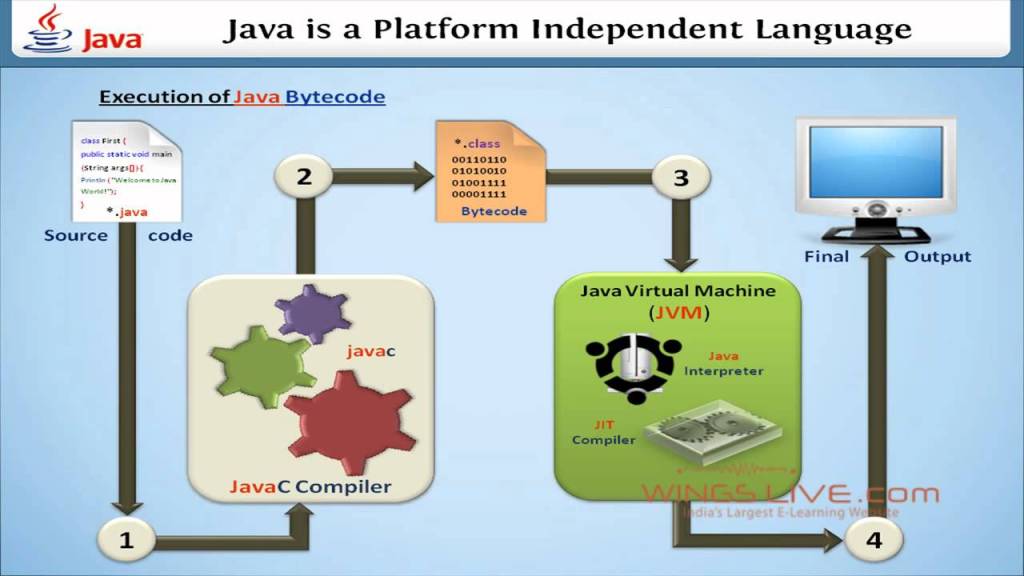
Platform-independency (Write Once Run Anywhere)
Write Once Run Anywhere (WORA) is a popular programming catchphrase introduced by Sun Microsystems to describe Java’s cross-platform capabilities.
It meant you could create a Java program on, let’s say, Windows, compile it to bytecode, and run the application on any other platform that supports a Java Virtual Machine (JVM).
In this case, a JVM serves as an abstraction level between the code and the hardware.
All major operating systems including Windows, Mac OS, and Linux support JVM. And unless you’re writing a program that relies mostly on platform-specific features and UI, you can share — maybe not all — but a big chunk of bytecode.
Distributed language for easy remote collaboration
Java was designed as a distributed language meaning that it has an integrated mechanism for sharing data and programs among multiple computers for improved performance and efficiency.
Unlike other languages, where you have to use external APIs for distribution, Java offers this technology at its core. Java-specific methodology for distributed computing is called Remote Method Invocation (RMI).
Using RMI allows you to bring all Java benefits, such as security, platform-independency and object-oriented programming, to distributed computing.
Apart from that, it also supports Socket Programming and the distribution methodology of CORBA for sharing objects between programs written in different languages.
Automatic memory management
Java developers don’t have to worry about manually writing code for memory management tasks thanks to automatic memory management (AMM), also used in the Swift programming language, and garbage collection, an application that automatically handles allocation and deallocation of memory. What exactly does it mean?
A program’s effectiveness is directly linked to memory — and memory is limited. By using languages with manual management, developers risk forgetting to allocate memory resulting in increased memory footprint and lagging.
A garbage collector can locate objects that are no longer referenced by your program and remove them.
Despite the fact that it affects your program’s CPU, you can reduce or prevent it with smart optimization and tuning.
Multithreading:
Threads share the same memory area so switching between them takes little time. They are also independent, so if one thread faces exception, it doesn’t affect other threads. This is especially useful for gaming and animation-heavy programs.
Drawbacks of programming in Java
Here are the cons you want to know before writing your next project in Java.
Paid the commercial license
Oracle recently announced that they will start charging Java Standard Edition 8 for “business, commercial, or production” use starting in 2019. To get all new updates and bug fixes, you’ll need to pay by the number of users or per processor.
Today, the current version of Java is free and available for redistribution for general purpose computing.
To prepare for the change, each company has to evaluate how much of Java they use and seek an alternative technology if the price upgrade promises to be too painful.
Poor performance
Any high-level language has to deal with poor performance due to the compilation and abstraction level of a virtual machine. However, it’s not the only reason for Java’s often criticized speed.
Take garbage collector, a useful feature that unfortunately can lead to significant performance problems if it takes more than 20 percent of CPU time.
Bad caching configuration can also cause excessive memory and garbage collection usage. There are also thread deadlocks that happen when several threads are trying to access the same resource, and — every Java developer’s nightmare — Out-of-Memory errors.
Although each of these problems can be prevented with skillful planning, they do add up and can cause different volumes of damage.
Far from a native look and feel on the desktop
To create a program’s graphical user interface (GUI), developers use different language-specific tools. Thus, for Android apps, there’s Android Studio that helps create apps that look and feel native. However, when it comes to desktop UI, Java noticeably lacks.
There are a few GUI builders Java programmers can choose from: Swing, SWT, JavaFX, JSF being the most popular. Swing is old but reliable, cross-platform, and already integrated in various Java IDEs including Eclipse and NetBeans.
But unless you’re using templates, you’ll notice interface inconsistencies. SWT uses native components but it’s not suitable for complicated UI. JavaFX is clean and modern-looking, but it’s not very mature.
Overall, choosing a good fit for your GUI building on Java requires additional research.
Verbose and complex code
When the code is verbose, it means it uses too many words. While it may seem an advantage when you’re trying to understand the language, long, over-complicated sentences make code less readable and scannable.
By trying to emulate English, many high-level languages tend to make too much noise.
Java, created to tone down the unapproachable C++, forces programmers to type exactly what they mean which makes the language more transparent to non-experts but unfortunately — less compact.
If we compare Java to its rival Python, we can see how clear Python code appears: It doesn’t require semicolons; uses “and,” “or,” and “not” as operators instead of Java’s “&&,” “||,” and “!”; and generally has fewer bells and whistles such as parentheses or curly braces.
If you want to see where Java is used, you are not too far away. Open your Android phone and any app, they are actually written in Java programming language, with Google’s Android API, which is similar to JDK. A couple of years back, Android has provided a much-needed boost, and today many Java programmer is Android App developers. By the way, Android uses different JVM and different packaging.
Server Apps at the Financial Services Industry
Java is very big in Financial Services. Lots of global Investment banks like Goldman Sachs, Citigroup, Barclays, Standard Charted, and other banks use Java for writing front and back office electronic trading systems, writing settlement and confirmation systems, data processing projects, and several others.
Java is mostly used to write a server-side application, mostly without any front end, which receives data from one server (upstream), processes it and sends it to other processes (downstream).
Java Swing was also popular for creating thick client GUIs for traders, but now C# is quickly gaining market share in that space, and Swing is out of its breath.
Java Web applications
Java is also big on E-commerce and web application space. You have a lot of RESTfull services being created using Spring MVC, Struts 2.0, and similar frameworks. Even simple Servlet, JSP, and Struts based web applications are quite popular on various government projects.
Many governments, healthcare, insurance, education, defense, and several other departments have their web application built in Java.
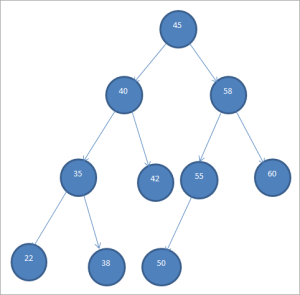
A binary search tree (BST), sometimes also called an ordered or sorted binary tree, is a node-based binary tree data structure which has the following properties:
The left subtree of a node contains only nodes with keys less than the node’s key.
The right subtree of a node contains only nodes with keys greater than the node’s key.
The left and right subtree must each also be a binary search tree.
There must be no duplicate nodes.
Generally, the information represented by each node is a record rather than a single data element. However, for sequencing purposes, nodes are compared according to their keys rather than any part of their associated records. for more java online course
The major advantage of binary search trees over other data structures is that the related sorting algorithms and search algorithms such as in-order traversal can be very efficient.
Binary search trees are a fundamental data structure used to construct more abstract data structures such as sets, multisets, and associative arrays.
Operations:
Insert(int n) : Add a node the tree with value n. Its O(lgn)
Find(int n) : Find a node the tree with value n. Its O(lgn)
Delete (int n) : Delete a node the tree with value n. Its O(lgn)
Display(): Prints the entire tree in increasing order. O(n).
Detail Explanations for the Operations:
Find(int n):
Its very simple operation to perform.
start from the root and compare root.data with n
if root.data is greater than n that means we need to go to the left of the root.
if root.data is smaller than n that means we need to go to the right of the root.
if any point of time root.data is equal to the n then we have found the node, return true.
if we reach to the leaves (end of the tree) return false, we didn’t find the element
Search()
Searching a node in binary search is very easy. You just need to traverse left (if smaller) and right (if greater) according to value to be found.
Algorithm:
If node to be found is equal to root, then search is successful
If node to be found is smaller than root , then traverse left subtree.
If node to be found is greater than root, then traverse right subtree
Repeat above steps recursively until you find the node.
Insert()
Insert node operation is also easy operation. You just need to compare it with root and traverse left (if smaller) or right(if greater) according to value of node to be inserted.
Algorithm:
Make root node as current node
If node to be inserted < root
If it has left child then traverse left
If it do not have left child, insert node here
If node to be inserted > root
If it have right child, traverse right
If it do not have right child, insert node here.
Order-based methods and deletion.
An important reason that BSTs are widely used is that they allow us to keep the keys in order. As such, they can serve as the basis for implementing the numerous methods in our ordered symbol-table API. Learn more programming skills from Learn Java Online
Minimum and maximum: If the left link of the root is null, the smallest key in a BST is the key at the root; if the left link is not null, the smallest key in the BST is the smallest key in the subtree rooted at the node referenced by the left link. Finding the maximum key is similar, moving to the right instead of to the left.
Floor and ceiling: If a given key key is less than the key at the root of a BST, then the floor of key (the largest key in the BST less than or equal to key) must be in the left subtree. If key is greater than the key at the root, then the floor of key could be in the right subtree, but only if there is a key smaller than or equal to key in the right subtree; if not (or if key is equal to the key at the root) then the key at the root is the floor of key. Finding the ceiling is similar, interchanging right and left.
Selection: Suppose that we seek the key of rank k (the key such that precisely k other keys in the BST are smaller). If the number of keys t in the left subtree is larger than k, we look (recursively) for the key of rank k in the left subtree; if t is equal to k, we return the key at the root; and if t is smaller than k, we look (recursively) for the key of rank k – t – 1 in the right subtree.
Rank: If the given key is equal to the key at the root, we return the number of keys t in the left subtree; if the given key is less than the key at the root, we return the rank of the key in the left subtree; and if the given key is larger than the key at the root, we return t plus one (to count the key at the root) plus the rank of the key in the right subtree.
Delete the minimum and maximum: For delete the minimum, we go left until finding a node that that has a null left link and then replace the link to that node by its right link. The symmetric method works for delete the maximum.
Delete: We can proceed in a similar manner to delete any node that has one child (or no children), but what can we do to delete a node that has two children? We are left with two links, but have a place in the parent node for only one of them. An answer to this dilemma, first proposed by T. Hibbard in 1962, is to delete a node x by replacing it with its successor. Because x has a right child, its successor is the node with the smallest key in its right subtree. The replacement preserves order in the tree because there are no keys between x.key and the successor’s key. We accomplish the task of replacing x by its successor in four (!) easy steps:
Save a link to the node to be deleted in t
Set x to point to its successor min(t.right).
Set the right link of x (which is supposed to point to the BST containing all the keys larger than x.key) to deleteMin(t.right), the link to the BST containing all the keys that are larger than x.key after the deletion.
Set the left link of x (which was null) to t.left (all the keys that are less than both the deleted key and its successor).
Advantages:
Compared to linear search (checking each element in the array starting from the first), binary search is much faster. Linear search takes, on average N/2 comparisons (where N is the number of elements in the array), and worst case N comparisons. Binary search takes an average and worst-case log2(N)log2(N) comparisons. So for a million elements, linear search would take an average of 500,000 comparisons, whereas binary search would take 20. For more details Java Certification Course
It’s a fairly simple algorithm, though people get it wrong all the time.
It’s well known and often implemented for you as a library routine.
Disadvantages:
It’s more complicated than linear search, and is overkill for very small numbers of elements.
It works only on lists that are sorted and kept sorted. That is not always feasable, especially if elements are constantly being added to the list.
It works only on element types for which there exists a less-than relationship. Some types simply cannot be sorted (though this is rare).
There is a great lost of efficiency if the list does not support random-access. You need, for example, to immediately jump to the middle of the list. If your list is a plain array, that’s great. If it’s a linked-list, not so much. Depending on the cost of your comparison operation, the cost of traversing a non-random-access list could dwarf the cost of the comparisons.
There are even faster search methods available, such as hash lookups. However a hash lookup requires the elements to be organized in a much more complicated data structure (a hash table, not a list).
Example:
Class BinarySearchTree {
class Node {
int key;
Node left, right;
public Node(int item) {
key = item;
left = right = null;
}
}
Node root;
BinarySearchTree() {
root = null;
}
void insert(int key) {
root = insertRec(root, key);
}
Node insertRec(Node root, int key) {
if (root == null) {
root = new Node(key);
return root;
}
if (key < root.key)
root.left = insertRec(root.left, key);
else if (key > root.key)
root.right = insertRec(root.right, key);
return root;
}
void inorder() {
inorderRec(root);
}
void inorderRec(Node root) {
if (root != null) {
inorderRec(root.left);
System.out.println(root.key);
inorderRec(root.right);
}
}
public static void main(String[] args) {
BinarySearchTree tree = new BinarySearchTree();
tree.insert(50);
tree.insert(30);
tree.insert(20);
tree.insert(40);
tree.insert(70);
tree.insert(60);
tree.insert(80);
tree.inorder();
}
}
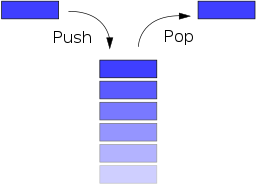
The Java Stack class, java.util.Stack, is a classical stack data structure. You can push elements to the top of a JavaStack and pop them again, meaning read and remove the elements from the top of the stack.
The Java Stack class actually implements the Java List interface, but you rarely use a Stack as a List – except perhaps if you need to inspect all elements currently stored on the stack.
Please note, that the Java Stack class is a subclass of Vector, an older Java class which is synchronized. This synchronization adds a small overhead to calls to all methods of a Stack. Learn programming skills from Core Java Online Training
Additionally, the Vector class uses several older (no longer recommended) parts of Java, like the Enumeration which is superseded by the Iterator interface. If you want to avoid these issues you can use a Java Deque as a stack instead.
A Stack is a Last In First Out (LIFO) data structure. It supports two basic operations called push and pop. The push operation adds an element at the top of the stack, and the pop operation removes an element from the top of the stack.
Java Stack Methods:
Java Stack extends Vector class with the following five operations only.
boolean empty(): Tests if this stack is empty.
E peek(): Looks at the object at the top of this stack without removing it from the stack.
E pop() : Removes the object at the top of this stack and returns that object as the value of this function.
E push(E item) : Pushes an item onto the top of this stack.
int search(Object o) : Returns the 1-based position where an object is on this stack.
Stack Important Points:
Stack class allow to store Heterogeneous elements.
Stack work on Last in First out (LIFO) manner.
Stack allow to store duplicate values.
Stack class is Synchronized.
Initial 10 memory location is create whenever object of stack is created and it is re-sizable.
Stack also organizes the data in the form of cells like Vector.
Stack is one of the sub-class of Vector. For more info Java Online Course
push() Method:
To add an element to the top of the stack, we use the push() method.
Example:
import java.util.Stack;
class Main {
public static void main(String[] args) {
Stack<String> animals= new Stack<>();
// Add elements to Stack
animals.push("Dog");
animals.push("Horse");
animals.push("Cat");
System.out.println("Stack: " + animals);
}
}
pop() Method:
To remove an element from the top of the stack, we use the pop() method.
import java.util.Stack;
class Main {
public static void main(String[] args) {
Stack<String> animals= new Stack<>();
// Add elements to Stack
animals.push("Dog");
animals.push("Horse");
animals.push("Cat");
System.out.println("Initial Stack: " + animals);
// Remove element stacks
String element = animals.pop();
System.out.println("Removed Element: " + element);
}
}
Peek at Top Element of Stack:
Stack<String> stack = new Stack<String>();
stack.push("1");
String topElement = stack.peek();
Example:
import java.io.*;
import java.util.*;
class Test
{
static void stack_push(Stack<Integer> stack)
{
for(int i = 0; i < 5; i++)
{
stack.push(i);
}
}
static void stack_pop(Stack<Integer> stack)
{
System.out.println("Pop :");
for(int i = 0; i < 5; i++)
{
Integer y = (Integer) stack.pop();
System.out.println(y);
}
}
static void stack_peek(Stack<Integer> stack)
{
Integer element = (Integer) stack.peek();
System.out.println("Element on stack top : " + element);
}
static void stack_search(Stack<Integer> stack, int element)
{
Integer pos = (Integer) stack.search(element);
if(pos == -1)
System.out.println("Element not found");
else
System.out.println("Element is found at position " + pos);
}
public static void main (String[] args)
{
Stack<Integer> stack = new Stack<Integer>();
stack_push(stack);
stack_pop(stack);
stack_push(stack);
stack_peek(stack);
stack_search(stack, 2);
stack_search(stack, 6);
}
}
A doubly-linked list is a linked data structure that consists of a set of sequentially linked records called nodes. Each node contains two fields, called links that are references to the previous and to the next node in the sequence of nodes.
The beginning and ending nodes previous and next links, respectively, point to some kind of terminator, typically a sentinel node or null, to facilitate traversal of the list.
If there is only one sentinel node, then the list is circularly linked via the sentinel node. It can be conceptualized as two singly linked lists formed from the same data items, but in opposite sequential orders. For more info Java Online Classes
The two node links allow traversal of the list in either direction. While adding or removing a node in a doubly-linked list requires changing more links than the same operations on a singly linked list.
The operations are simpler and potentially more efficient, because there is no need to keep track of the previous node during traversal or no need to traverse the list to find the previous node, so that its link can be modified.
Memory Representation of a doubly linked list
Memory Representation of a doubly linked list is shown in the following image. Generally, doubly linked list consumes more space for every node and therefore, causes more expansive basic operations such as insertion and deletion.
However, we can easily manipulate the elements of the list since the list maintains pointers in both the directions (forward and backward).
In the following image, the first element of the list that is i.e. 13 stored at address 1. The head pointer points to the starting address 1. Since this is the first element being added to the list therefore the prev of the list contains null. The next node of the list resides at address 4 therefore the first node contains 4 in its next pointer.
We can traverse the list in this way until we find any node containing null or -1 in its next part. Learn more programming skills from Core Java Online Training
Operations:
NOTE: we are two references here, head and tail. Head points the start of the linked list and tail points to the last node of the linked list.
Add at the Start : Add a node the beginning of the linked list. Its O(1). If size is 0 then make the new node as head and tail else put the at the start, change the head and do not change the tail.
Add at the End : Add a node at the end of the linked list. its O(1) since we have tail reference. If size is 0 then make the new node as head and tail else put node at the end of the list using tail reference and make the new node as tail.
Delete at the Start : Delete a node from beginning of the linked list and make the head points to the 2nd node in the list. Its O(1).
Get Size: returns the size of the linked list.
Get Element at Index : Return the element at specific index, if index is greater than the size then return –1. its O(n) in worst case.
Print: Prints the entire linked list. O(n). For more additional skills Core Java Online Course
Advantages over singly linked list 1) A DLL can be traversed in both forward and backward direction. 2) The delete operation in DLL is more efficient if pointer to the node to be deleted is given. 3) We can quickly insert a new node before a given node.
Disadvantages over singly linked list 1) Every node of DLL Require extra space for an previous pointer. It is possible to implement DLL with single pointer though. 2) All operations require an extra pointer previous to be maintained. For example, in insertion, we need to modify previous pointers together with next pointers. For example in following functions for insertions at different positions, we need 1 or 2 extra steps to set previous pointer.
Example:
public class DoublyLinkedList {
class Node{
int data;
Node previous;
Node next;
public Node(int data) {
this.data = data;
}
}
Node head, tail = null;
public void addNode(int data) {
Node newNode = new Node(data);
if(head == null) {
head = tail = newNode;
head.previous = null;
tail.next = null;
}
else {
tail.next = newNode;
newNode.previous = tail;
tail = newNode;
tail.next = null;
}
}
public void display() {
Node current = head;
if(head == null) {
System.out.println("List is empty");
return;
}
System.out.println("Nodes of doubly linked list: ");
while(current != null) {
System.out.print(current.data + " ");
current = current.next;
}
}
public static void main(String[] args) {
DoublyLinkedList dList = new DoublyLinkedList();
dList.addNode(1);
dList.addNode(2);
dList.addNode(3);
dList.addNode(4);
dList.addNode(5);
dList.display();
}
}
Quicksort algorithm is one of the most used sorting algorithm, especially to sort large lists/arrays. Quicksort is a divide and conquer algorithm, which means original array is divided into two arrays, each of them is sorted individually and then sorted output is merged to produce the sorted array.
On the average, it has O(n log n) complexity, making quicksort suitable for sorting big data volumes.
In more standard words, quicksort algorithm repeatedly divides an un-sorted section into a lower order sub-section and a higher order sub-section by comparing to a pivot element. For more additional info Java Online Course
At the end of recursion, we get sorted array. Please note that the quicksort can be implemented to sort “in-place”.
This means that the sorting takes place in the array and that no additional array need to be created.
There are many different versions of quickSort that pick pivot in different ways.
Always pick first element as pivot.
Always pick last element as pivot (implemented below)
Pick a random element as pivot.
Pick median as pivot.
The key process in quickSort is partition(). Target of partitions is, given an array and an element x of array as pivot, put x at its correct position in sorted array and put all smaller elements (smaller than x) before x, and put all greater elements (greater than x) after x. All this should be done in linear time. For more info Java Online Classes
The algorithm processes the array in the following way.
Set the first index of the array to left and loc variable. Set the last index of the array to right variable. i.e. left = 0, loc = 0, en d = n – 1, where n is the length of the array.
Start from the right of the array and scan the complete array from right to beginning comparing each element of the array with the element pointed by loc.
Ensure that, a[loc] is less than a[right].
If this is the case, then continue with the comparison until right becomes equal to the loc. If a[loc] > a[right], then swap the two values. And go to step
Set, loc = right
start from element pointed by left and compare each element in its way with the element pointed by the variable loc. Ensure that a[loc] > a[left]
if this is the case, then continue with the comparison until loc becomes equal to left.
[loc] < a[right], then swap the two values and go to step 2.
Set, loc = left.
Algorithm:
PARTITION (ARR, BEG, END, LOC)
Step 1: [INITIALIZE] SET LEFT = BEG, RIGHT = END, LOC = BEG, FLAG =
Step 2: Repeat Steps 3 to 6 while FLAG =
Step 3: Repeat while ARR[LOC] <=ARR[RIGHT] AND LOC != RIGHT SET RIGHT = RIGHT – 1 [END OF LOOP]
Step 4: IF LOC = RIGHT SET FLAG = 1 ELSE IF ARR[LOC] > ARR[RIGHT] SWAP ARR[LOC] with ARR[RIGHT] SET LOC = RIGHT [END OF IF]
Step 5: IF FLAG = 0 Repeat while ARR[LOC] >= ARR[LEFT] AND LOC != LEFT SET LEFT = LEFT + 1 [END OF LOOP]
Step 6:IF LOC = LEFT SET FLAG = 1 ELSE IF ARR[LOC] < ARR[LEFT] SWAP ARR[LOC] with ARR[LEFT] SET LOC = LEFT [END OF IF] [END OF IF]
Step 7: [END OF LOOP]
Step 8: END
QUICK_SORT (ARR, BEG, END)
Step 1: IF (BEG < END) CALL PARTITION (ARR, BEG, END, LOC) CALL QUICKSORT(ARR, BEG, LOC – 1) CALL QUICKSORT(ARR, LOC + 1, END) [END OF IF]
Step 2: END
Algorithm Analysis:
Time Complexity:
In the best case, the algorithm will divide the list into two equal size sub-lists. So, the first iteration of the full n-sized list needs O(n). Sorting the remaining two sub-lists with n/2 elements takes 2*O(n/2) each. As a result, the QuickSort algorithm has the complexity of O(n log n).
In the worst case, the algorithm will select only one element in each iteration, so O(n) + O(n-1) + … + O(1), which is equal to O(n2).
On the average QuickSort has O(n log n) complexity, making it suitable for big data volumes. For programming skills on Java Certification Course
QuickSort vs MergeSort:
Let’s discuss in which cases we should choose QuickSort over MergeSort.
Although both Quicksort and Mergesort have an average time complexity of O(n log n), Quicksort is the preferred algorithm, as it has an O(log(n)) space complexity. Mergesort, on the other hand, requires O(n) extra storage, which makes it quite expensive for arrays.
Quicksort requires to access different indices for its operations, but this access is not directly possible in linked lists, as there are no continuous blocks; therefore to access an element we have to iterate through each node from the beginning of the linked list. Also, Mergesort is implemented without extra space for LinkedLists.
In such case, overhead increases for Quicksort and Mergesort is generally preferred.
Example:
public class QuickSort {
public static void main(String[] args) {
int[] arr = {4, 5, 1, 2, 3, 3};
quickSort(arr, 0, arr.length-1);
System.out.println(Arrays.toString(arr));
}
public static void quickSort(int[] arr, int start, int end){
int partition = partition(arr, start, end);
if(partition-1>start) {
quickSort(arr, start, partition - 1);
}
if(partition+1<end) {
quickSort(arr, partition + 1, end);
}
}
public static int partition(int[] arr, int start, int end){
int pivot = arr[end];
for(int i=start; i<end; i++){
if(arr[i]<pivot){
int temp= arr[start];
arr[start]=arr[i];
arr[i]=temp;
start++;
}
}
int temp = arr[start];
arr[start] = pivot;
arr[end] = temp;
return start;
}
}
public class QuickSort {
public static void main(String[] args) {
int[] x = { 9, 2, 4, 7, 3, 7, 10 };
System.out.println(Arrays.toString(x));
int low = 0;
int high = x.length - 1;
quickSort(x, low, high);
System.out.println(Arrays.toString(x));
}
public static void quickSort(int[] arr, int low, int high) {
if (arr == null || arr.length == 0)
return;
if (low >= high)
return;
// pick the pivot
int middle = low + (high - low) / 2;
int pivot = arr[middle];
// make left < pivot and right > pivot
int i = low, j = high;
while (i <= j) {
while (arr[i] < pivot) {
i++;
}
while (arr[j] > pivot) {
j--;
}
if (i <= j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
i++;
j--;
}
}
// recursively sort two sub parts
if (low < j)
quickSort(arr, low, j);
if (high > i)
quickSort(arr, i, high);
}
}
The AWS SDK for Java provides a Java API for Amazon Web Services. Using the SDK, you can easily build Java applications that work with Amazon S3, Amazon EC2, Amazon SimpleDB, and more.
We regularly add support for new services to the AWS SDK for Java. For a list of the supported services and their API versions that are included with each release of the SDK. For more info Java Online Classes
Eclipse IDE Support
If you develop code using the Eclipse IDE, you can use the AWS Toolkit for Eclipse to add the AWS SDK for Java to an existing Eclipse project or to create a new AWS SDK for Java project.
The toolkit also supports creating and uploading Lambda functions, launching and monitoring Amazon EC2 instances, managing IAM users and security groups, a AWS CloudFormation template editor, and more.
Developing AWS Applications for Android
If you’re an Android developer, Amazon Web Services publishes an SDK made specifically for Android development: the AWS Mobile SDK for Android.
Viewing the SDK’s Revision History
To view the release history of the AWS SDK for Java, including changes and supported services per SDK version. Learn more skills from Java Online Training
Building Java Reference Documentation for Earlier SDK versions
The AWS SDK for Java API Reference represents the most recent version of the SDK. If you’re using an earlier SDK version, you might want to access the SDK reference documentation that matches the version you’re using.
The easiest way to build the documentation is using Apache’s Maven build tool. Download and install Maven first if you don’t already have it on your system, then use the following instructions to build the reference documentation.
To build reference documentation for an earlier SDK version
Locate and select the SDK version that you’re using on the releases page of the SDK repository on GitHub.
Choose either the zip (most platforms, including Windows) or tar.gz (Linux, macOS, or Unix) link to download the SDK to your computer.
Unpack the archive to a local directory.
On the command line, navigate to the directory where you unpacked the archive, and type the following.
mvn javadoc:javadoc
After building is complete, you’ll find the generated HTML documentation in the aws-java-sdk/target/site/apidocs/ directory.
Enabling Metrics for the AWS SDK for Java
The AWS SDK for Java can generate metrics for visualization and monitoring with CloudWatch that measure:
your application’s performance when accessing AWS
the performance of your JVMs when used with AWS
runtime environment details such as heap memory, number of threads, and opened file descriptors
Note
The AWS SDK Metrics for Enterprise Support is another option for gathering metrics about your application. SDK Metrics is an AWS service that publishes data to Amazon CloudWatch and enables you to share metric data with AWS Support for easier troubleshooting. Get more programming skills from Java Online Course
How to Enable AWS SDK for Java Metric Generation
AWS SDK for Java metrics are disabled by default. To enable it for your local development environment, include a system property that points to your AWS security credential file when starting up the JVM. For example:
You need to specify the path to your credential file so that the SDK can upload the gathered datapoints to CloudWatch for later analysis.
Note
If you are accessing AWS from an Amazon EC2 instance using the Amazon EC2 instance metadata service, you don’t need to specify a credential file. In this case, you need only specify:
Dcom.amazonaws.sdk.enableDefaultMetrics
All metrics captured by the SDK for Java are under the namespace AWSSDK/Java, and are uploaded to the CloudWatch default region (us-east-1). To change the region, specify it by using the cloudwatchRegion attribute in the system property. For example, to set the CloudWatch region to us-west-2, use:
Once you enable the feature, every time there is a service request to AWS from the AWS SDK for Java, metric data points will be generated, queued for statistical summary, and uploaded asynchronously to CloudWatch about once every minute. Once metrics have been uploaded, you can visualize them using the AWS Management Console and set alarms on potential problems such as memory leakage, file descriptor leakage, and so on.
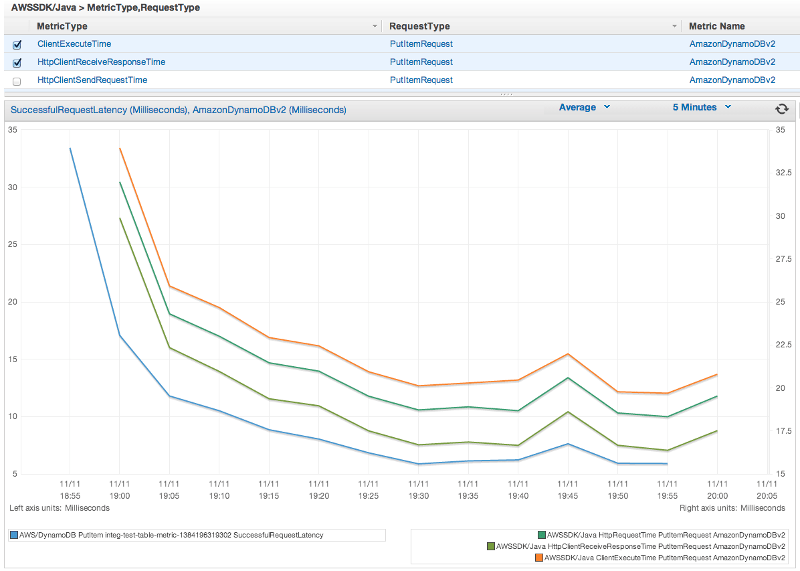
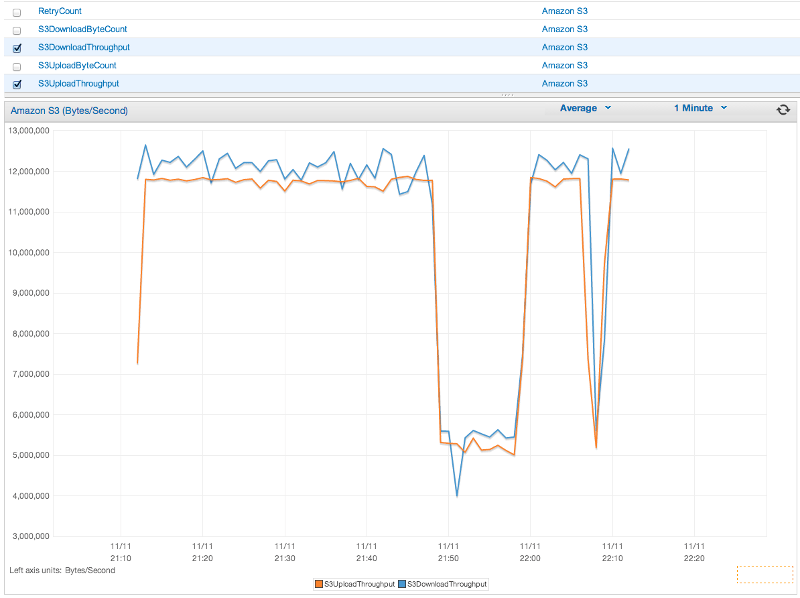
Available Metric Types
The default set of metrics is divided into three major categories:
AWS Request Metrics
Covers areas such as the latency of the HTTP request/response, number of requests, exceptions, and retries.
AWS Service Metrics
Include AWS service-specific data, such as the throughput and byte count for S3 uploads and downloads.
Machine Metrics
Cover the runtime environment, including heap memory, number of threads, and open file descriptors.