Since Oracle changed their Java licensing rules and customers might be obliged to purchase a commercial license for their Java installations, it becomes a real challenge to detect and correctly interpret all Oracle Java software present on the infrastructure of your organisation and determine your actual Java license need.
Determining the correct update level for your Java installations might be on top of your list. It is also important to determine whether an installation is covered by other Oracle Software installations or even by third-party software installations.
Next to that, Oracle’s license metric definitions need to be applied to the software that has been discovered. Meaning all processors or users need to be identified and counted against Oracle’s licensing conditions. For more details Servicenow Training
This means keeping in mind all Oracle’s licensing rules including Oracle’s Partitioning Policy.
Extended Java detection with ServiceNow
If you are already a ServiceNow customer, you might have ServiceNow Discovery up and running within the organisation. If so, detection and interpretation of Oracle Java software on Windows-based platforms is available as out-of-the-box functionality.
On top of that, Softline Solutions has developed a new probe and sensor functionality to be added to ServiceNow Discovery, enabling you to determine Java installations on Linux-based platforms as well.
By doing so, complete coverage of your infrastructure can be established for all Java installations. Some characteristics of the functionality this added probe and sensor will provide: Learn more skills from Servicenow Certification
Oracle Java Detection on update patch level, enabling you to differentiate between paid versions of Oracle Java and free/open versions;
Oracle Java Detection results are added to existing ServiceNow CMDB installation tables, provided Discovery is up and running;
Oracle Java Installation records can be identified by their source and patch-level as well, while this information is also being stored in added columns within ServiceNow;
No extra authorisations or privileges are necessary to execute the additional functionality.
Determining Java Compliance and Security risks
When your Oracle Java detection is successful, you are now facing another challenge: determining your license need and choosing the most applicable metric for your organisation accordingly.
By enabling the SAM Pro module within ServiceNow it is also possible to execute reconciliation jobs and apply Oracle’s licensing rules to the Java software that has been detected. Learn more skills from Servicenow Developer Training
Softline Solutions can assist in creating basic or extended Oracle Java License Position Reports within ServiceNow. Depending on your needs, these reports can encompass:
Normalisation of the data;
Exclusion of servers that contain Java software but are covered by a different Oracle software installation;
Identification and exclusion of servers that contain embedded Java software and are covered by a third-party software license;
Oracle’s core factor rules, including partitioning rules, therefore taking into account virtual machines, hosts and cluster information;
Calculate a break-even point regarding the Oracle License metrics (either Processor or NUP) that can be chosen to cover your Oracle Java installations;
Identify Java installations that might imply security risks (CVSS rated).
Tableau is an awesome data visualization tool that is used for data analysis and business intelligence. Tableau helps us to create a wide variety of visualization to interactively present the data and showcase insights. It provides tools that allow us to drill down data and see the impact in a visual format that can be easily understood.
Here, we will be discussing about how to embed Tableau dashboards in Angular applications. If you are new to Tableau Training
Tableau Javascript API
We are going to utilize Tableau Javascript API for embedding the report.
The Tableau JavaScript API uses an object model. The entry point into the object model is to instantiate a new Viz object as follows:
var viz = new tableau.Viz( /* params omitted */ );
Steps to do
Prerequisites — Get the visualization url of your Tableau report/dashboard
Let’s follow the below steps for embedding the report in Angular application:-
Step 1: Adding API file in index.html
As a first step we need to add the below Tableau API file in the index.html of our Angular application. Get more skills from Tableau Advanced Training
This div container will be used to hold the Tableau content.
Step 3: Invoking Tableau API
In our Angular component, we need to declare a variable named ‘tableau’ because it is the reference for Tableau API.
declare var tableau: any;
Add a component variable to hold the Viz object that is going to be created.
viz: any;
Finally, in the ngOnInit method, instantiate a new Viz object, call the Viz constructor and pass a reference to the div container on the HTML page, the URL of the visualization on Tableau Server, and a set of options. Get more from Tableau Server Training
var placeholderDiv = document.getElementById('vizContainer');
// Replace this url with the url of your Tableau dashboard
var url = 'https://public.tableau.com/views/All_Reports_0/Dashboard1?:embed=y&:display_count=yes';
var options = {
hideTabs: true,
width: "80%",
height: "500px",
onFirstInteractive: function() {
// The viz is now ready and can be safely used.
console.log("Run this code when the viz has finished loading.");
}
};
// Creating a viz object and embed it in the container div.
this.viz = new tableau.Viz(placeholderDiv, url, options);
And we are done, now Tableau dashboard will get displayed in your Angular application as shown below 🙂
What is the usage of ‘options’?
While initializing a Viz object, we can specify how the view is initially rendered by passing options like:
Width and Height
Show or hide the toolbar and tabs
Call a callback function when the visualization becomes interactive or when the width and height are known
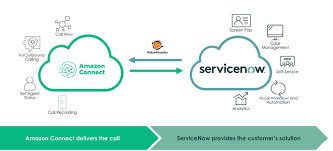
OnCommand Insight integrates with ServiceNow management software to provide greater value than the products have separately.
Using a Python script, Insight can integrate data with ServiceNow, synchronizing the following information:
Storage asset data for ServiceNow servers
Host and VM URLs for ServiceNow servers
Relationships between Hosts/VMs and Storage
Preparation and prerequisites for Service Now integration
The necessary preparations and prerequisites must be satisfied for ServiceNow, Insight, and the Python middleware connector prior to integration.
Recommended workflow
The following workflow is strongly recommended when integrating ServiceNow with Insight:
Deploy the Python middleware connector in your development instance first.
Once you have confirmed all faults have been identified and corrected in your development instance, deploy the connector in your test/stage instance.
Once you have confirmed correct operation in your staging instance, deploy the connector in your production instance. For more info Servicenow Training
If problems are found during any of these stages, follow your rollback steps and disable the connector, then troubleshoot the problem and re-deploy.
General prerequisites:
You can use either a standalone host or VM (recommended) or the Insight server host/VM to host the python middleware connector.
It is highly recommended to backup the production Insight server and deploy it on a development instance.
ServiceNow must be accurately discovering servers in the CMDB.
Insight must be accurately discovering your storage and compute environments.
Port 443 and 80 to the Insight Server and ServiceNow Instance.
ServiceNow prerequisites:
It is highly recommended to use a development/test instance.
Permission to load ServiceNow update sets.
Permission to create users.
ServiceNow version Jakarta or later
Insight prerequisites:
It is highly recommended to use a development/test instance.
Permission to create users (Admin permissions).
Insight version 7.3.1 or later is supported, but to get the most out of Insight, use the latest version.
Python middleware connector prerequisites:
Python version 3.6 or greater installed.
When installing Python, check the box to enable all users. This sets Python for standard application install locations.
When installing Python, check the box to enable the installer to update the path. Otherwise, you will have to update the path manually.
Integrating ServiceNow with Insight requires several setup tasks.
About this task
The following tasks must be performed when integrating ServiceNow with Insight:
On the ServiceNow side:
Elevate Role
Install Update Sets
Set up users
On the Insight side:
Add the ServiceNow user
On the Python connector side:
Install Python
Install additional libraries
Initialize the connector
Edit the config.ini file
Test the connector
Synchronize the connector
Schedule daily task execution
Configuring ServiceNow for integration
Integrating ServiceNow with Insight requires several setup tasks.
About this task
The following tasks must be performed when integrating ServiceNow with Insight:
On the ServiceNow side:
Elevate Role
Install Update Sets
Set up users
On the Insight side:
Add the ServiceNow user
On the Python connector side:
Install Python
Install additional libraries
Initialize the connector
Edit the config.ini file
Test the connector
Synchronize the connector
Schedule daily task execution
Install update set
As part of the integration between ServiceNow and OnCommand Insight you must install an Update Set, which loads pre-configured data into ServiceNow in order to provide the connector with specific fields and tables for extracting and loading data.
Steps
Navigate to the remote update sets table in ServiceNow by searching for “Retrieved update sets”.
Click on Import Update Set from XML.
The update set is in the Python connector .zip file previously downloaded to your local drive (in our example, the C:\OCI2SNOW folder) in the \update_sets sub-folder. Click on Choose File and select the .xml file in this folder. Click Upload.
Once the Update Set is loaded, open it and click on Preview Update Set.
If errors are detected, you must correct them before you can commit the Update Set.
If there are no errors, click Commit Update Set.
Once the Update Set has been committed it will show on the System Update Sets > Update Sources page.
ServiceNow integration – Set up user
You must set up a ServiceNow user for Insight to connect with and synchronize data.
About this task
Steps
Create a services account in ServiceNow. Login to ServiceNow and navigate to system security > users and groups > users. Click on New.
Enter a user name. In this example, we will use “OCI2SNOW” as our integration user. Enter a password for this user.
Note: In this How-to we use a services account user named “OCI2SNOW”” across the documentation. You may use a different services account, but be sure it is consistent across your environment.
Right-click on the menu bar and click Save. This will allow you to stay on this user in order to add roles.
Click Edit and add the following roles to this user:
asset
import_transformer
rest_service
Click Save.
This same user must be added to OnCommand Insight. Log in to Insight as a user with Administrator permissions.
Navigate to Admin > Setup and click on the Users tab.
Click the Actions button and select Add user.
For name, enter “OCI2SNOW”. If you used a different user name above, enter that name here. Enter the same password you used for the ServiceNow user above. You may leave the email field blank.
Python can be installed on the Insight server or on a standalone host or VM.
Steps
On your VM or host, download Python 3.6 or later.
Choose custom installation and choose the following options. These are either necessary for proper connector script operation or are highly recommended.
Install launcher for all users
Add Python to the PATH
Install pip (which allows Python to install other packages)
Install tk/tcl and IDLE
Install the Python test suite
Install py launcher for all users
Associate files with Python
Create shortcuts for installed applications
Add python to environment variables
Precompile standard library
After Python is installed, install the “requests” and “psnow” Python libraries. Run the following command:python -m pip install requests pysnow
NOTE: This command might fail when you are operating in a proxy environment. To work around this issue, you need to manually download each one of the Python Libraries and run the install requests one by one and in the correct order.
The command will install several files.
Verify the Python libraries are installed correctly. Start Python using one of the following methods:
Open a cmd prompt and type python
On Windows, open Start and choose Python > python-<version>.exe
At the Python prompt, typemodules
Python will ask you to wait a moment while it gathers a list of modules, which it will then display.
DevOps sees the coming together of practices, philosophies, and tools that allow you to create services and applications very quickly. This means that you can improve on your apps and evolve them at a much faster rate than those developers who are using traditional software development processes.
We’ve talked about DevOps, in general, a great deal, but today, we’re going to dig a little deeper and take a look at Java DevOps specifically. Get more from DevOps Online Course
What is DevOps?
DevOps is simply a portmanteau of software DEVelopment and IT OPerations. It was first called agile operations and involves different disciplines in building, operating and evolving applications and services.
Using a DevOps model, you are bringing together your development team and your operations team, and their work is no longer in silos.
These teams, and sometimes together with the security and quality assurance teams, work together to bring about the new application – from developing, to testing, to deploying, and then to operating it.
Another significant characteristic – developers often use tools, which help automate processes that used to be done manually and, as such, are prone to error and take a much longer time to accomplish. Learn more skills from DevOps Training
They also use tools to quickly operate and support applications, as well as to be able to accomplish tasks without needing outside help, such as deploying code or allocating resources.
What is Java DevOps?
Java DevOps is simply applying DevOps practices and philosophies to Java app development. That means that compartmentalized teams are no longer needed when creating Java applications.
Some of the principles you should know include:
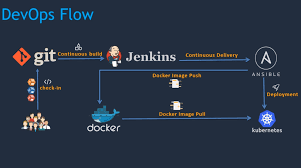
Continuous integration. This practice requires developers to periodically merge the code that they have written into a central repository. After the merge, tests and automated builds are executed. This allows a team to find issues and quickly quash out bugs, improve the application’s quality and then cut the time needed to validate your apps. It also helps your team release new updates faster.
Continuous delivery. This practice requires your team to release into production all code changes after it is written and then automatically built, and tested. If continuous integration puts your code changes onto a testing environment, continuous delivery puts it into a production environment. What does this mean? You will always have a production-ready Java application!
Microservices. DevOps make use of microservices. Instead of having one big monolithic Java application, your application is made up of smaller and independent applications. Learn more from Learn DevOps Online
Infrastructure as a code. This practice means that infrastructure is allocated and then managed by using code and development techniques. Cloud services can help your development and operations teams interact with infrastructure at a scale they are comfortable with. With infrastructure as a code, servers and infrastructure are deployed fast, automatically patched and can easily be duplicated. Your team can also automate configuration management, and also take advantage of policy as a code, where compliance with regulatory requirements is practically ensured.
DevOps take a people-first approach. Apart from bringing together your development, operations and other teams, DevOps require team members to understand the perspective of other members of the team. That may mean a developer is sharing his or her concerns with the team and a SysOp doing the same. This kind of understanding can enable team members to help each other, such as a developer building facilities and tools that another team member needs. As such, collaboration is not only encouraged by necessity. But even as you bring teams together, it also puts focus on accountability and ownership.
Java DevOps cuts the time to develop a Java application. This will help you deliver the right Java applications to end users faster, and even become more efficient as time wears on. You can also adapt faster to every changing market conditions and demands.
Better application quality. DevOps almost always require a shift to continuous integration, which means that every step of the application’s development is tested and monitored. Each change is also tested. It is because of this that Java DevOps can ensure that your Java applications have a positive experience for your users. Plus, DevOps can actually increase security, rather than hinder it.
You don’t get overwhelmed. You can manage and operate your applications, processes, and infrastructure at scale.
Considerations and Risk Mitigation
Here are the things that you should consider when shifting to DevOps for your Java projects.
Visibility: It would be very tiresome and difficult to check if your containers have the right configurations or do not contain spyware.
Vulnerabilities: If there are problems or if you need to update or remove components, it will be very difficult to keep up with different containers.
Consistency: There might be components that are not reviewed. And if you use microservices, that might also mean more configurations to be checked.
The good news is that there are tools that you can use to help you manage or minimize these risks. These tools include Artifactory, Sonatype Nexus, and RogueWave OpenLogic, as well as a number of open source and paid tools.
Choose the Right Tools
Right now, you have teams developing applications using different programming languages that make their software very complex. One application might have RubyGems, nugget packages, and NodeJS package systems, among others. The reason for this is that developers tend to use the programming language that they are comfortable with. Get details from Best DevOps Online Course
It helps that it is easy to manage these components, with little or no effort at all by automating the management processes.
Developers can also use Docker containers to introduce new components in just minutes, while also allowing them to grab entire stacks. Docker containers help make application development more flexible and faster.
However, you can easily get into trouble, and knowing the right tools can help mitigate that
risk. So how do you choose your tools? Choose tools that:
Have roles and rules that would define who could use certain components from a particular library.
Are able to integrate with release automation tools. It should also be able to, at the very least, warn you about risky components that are going to be included in your releases.
Can update components automatically.
Have a database of known vulnerabilities.
Have reporting and analytics features on components and the associated metadata.
Give you an easy way to organize and search for components.
Workday is an on-demand human capital and financial management software vendor. Workday software is a cloud-based ERP system that practices in HCM and financial management application software. It combines finance, HR and planning services with a single ERP system to provide better business experience. Workday software also integrates Machine learning to run the business operations smoothly.
Machine learning is an application of AI that facilitates systems to learn and improve automatically from experience. It focuses on the development of programs that help the systems to access data and learn automatically. For more details Workday training
Furthermore, we can see the integration of Workday with Machine learning. The future of this combination for business entities may be helpful.
Workday and Machine learning
Today most of the large business entities use advanced level technology for its smooth operations. Workday software is one of them. Workday provides the best human capital management services along with financial management. It also integrates the ERP system to the existing services that help management to make better decisions.
Workday software integrates Machine learning to provide better services than ever. Many business entities are using Workday services for its smooth operations. Today several transactions are held among large business entities. Every transaction is precious for them because these include monetary matters. So, every transaction within Workday describes a business decision. When it combines with machine learning, the result becomes the outcome of these transactions.
Machine learning algorithms verify this data along with customer decisions to provide better results. Today all workday activities include machine learning as an instance.
Finance is the lifeblood of every business. The workday financial management system automatically detects the errors within financial transactions that reduce the time for the analyst from manual detections. Learn more skills from Workday Online Training
Nowadays most companies include Machine learning to find out the errors or anomalies within the transactions, journal entries, etc. It helps to make quick decisions based on predictions by the systems. Workday software and machine learning are used alternatively to provide business operations faster and smoother.
These processes involve a lot of automation and reconciliation features that help customers by saving time while transacting. These include supplier invoice, customer payment matching, expense audit, etc. Machine learning applications like only one customer support, virtual personal assistant, product recommendations and social media services help in this regard very much.
So, we can say that using machine learning along with Workday will help large business entities to work faster and with security management. More info Workday Learning
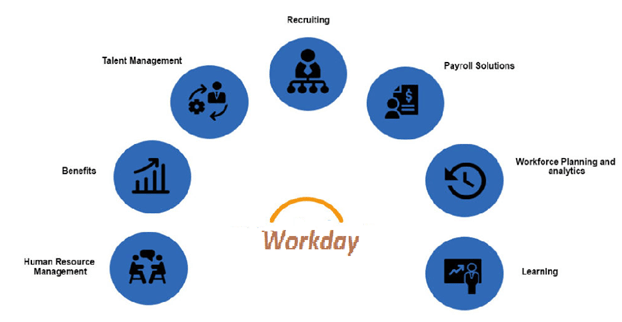
Workday features
Workday software has many features. It consists of several services that broadly help the organization. The key features of the workday are as follows;
Organization management
Performance management
Time tracking
Goal management
Career development and planning
Expense management
Talent management
Workforce analytics
Operations management
Payroll solutions and so on.
The above features are some of the many features of Workday. All these features provide different services to business entities. Mostly the financial transactions held between the business units and customers plays an important role.
These transactions may include a lot of errors while posting or performing. To overcome these errors, Workday initiates audits along with Machine learning techniques. This helps to identify the transactions with errors and make clear them as soon as possible.
Machine learning applications
There are many applications that Machine learning provides. These applications help us in our daily life. Few of them are as follows;
Social media services
Online customer support
Video Surveillance
Product recommendations
Virtual personal assistant and so on.
These applications help us a lot. Most of the companies are using these applications for their daily business. Furthermore, these applications provide seamless services to increase the business network. It saves time and money for the business very much.
When these applications combine with Workday software, they can create wonders. This combination will help the industry much more. It will help to solve many complex issues that occur in business. These services may increase customer satisfaction.
Furthermore, these activities keep the customer more engaged in the business. They can attract customers with different services and offers. This gives more satisfied customers to the industry. And the business will grow on to new heights.
Workday benefits
It provides real-time business insights along with financial capabilities. The product completely transforms enterprise finance.
It integrates different business systems and applications with automation and reconciliations. Furthermore, Machine learning features will save time while doing numerous transactions.
It also protects against security breaches and data threats in various ways. It provides the latest updates in its applications. It helps the business organization to apply new methods in its work.
In addition to this, it conducts regular audits to give seamless support to the business.
Moreover, there are so many benefits that Workday provides to every business entity and its customers. Get more skills from Workday HCM Online Training
All these benefits will give more satisfaction to the entities and their customers to continue their trust among each other. Furthermore, it brings both of them together on a single platform.
Workday reporting and analytics
This feature in Workday helps to identify the people’s way of thinking. It helps to predict the thing that engages people in one place. The key indicators shown in the organization chart helps to increase customer engagement. It also identifies the employee risk. This will make the entity more secure. In addition to this, it also protects various financial activities within the company.
Furthermore, this analytics helps the business to keep reporting on potential things. With this reporting tool, customer engagement can be improved in different ways. Here, Workday introduces a composite reporting tool that helps to combine various reports and displays in a single report. Multiple reports can be present with this feature one by one. Furthermore, it will help to view reports easily. Learn more from Workday Integration Online Training
Workday software reviews
Workday software has proven as the best solution for financial and human capital management services. Many giant companies have given their best reviews with their satisfaction using this product. It helps them very much. They had spoken about how the Workday software made their business days much easier.
Experts evaluate in their words that they used this software with full resources to make better business decisions. Its financial management and HR applications are very useful for any entity to make the best use of it. These applications made their daily business activities more flexible.
Furthermore, the data can be present in an easy way using this software that helps to understand it well. It also helps to solve real-world problems within an organization as people said.
Workday pricing
Workday software is subject to license. It offers different pricing solutions for its software and other products. In addition to this, it depends upon the size of the business and the employees using the software to quote the price. The price may increase according to the needs of the business. But it will add more credentials to the business.
According to a Workday consultant, it is said that the software is less expensive than others like Oracle, SAP, etc. It typically costs some thousand dollars in its installation. Furthermore, it depends upon the number of factors to quote the exact price of the software such as the number of employees, the size of the entity, business requirements, etc. Learn more from Workday HCM Training
Workday future growth
It is considered that Workday has a great future. Today the business entities are using these software services with a great deal. Every business entity and the customers also get satisfaction using this product.
Human capital management is an essential part of every business organization. With the use of Workday software along with Machine learning technology, every business entity gets the best solution for its HCM activities. Furthermore, Workday also provides financial management solutions to different business entities.
Finance is like a lifeblood for every business without which no business can prosper. Besides, Workday solutions provide the smooth maintenance of transactions across the industry. Every day a lot of monetary transactions are held between the customers and entities.
These transactions include journals, ledgers, banking transactions, etc. Furthermore, there may be some issues among these transactions. To solve these issues, it integrates with machine learning to provide the best solutions to business management. Machine learning applications help very much in this regard. They use AI techniques that solve many complex issues in less time.
So, it can be said that the integration of machine learning with Workday will help most businesses soon. Further, it will add customer satisfaction.
Thus, the above writings explain the integration of Workday software with Machine learning and its future. Workday software provides the best solutions to financial and human capital management. Furthermore, Workday and machine learning combine to set a trend among the business activities that run forever. It will create a new era of doing business with ease. Moreover, it adds more value to the customers.
One who wants to develop his career in this field can opt for Workday Studio Online Training from various online sources. This learning may enhance skills and knowledge to achieve new heights in a career.
Kubernetes has gained a great deal of traction for deploying applications in containers in production, because it provides a powerful abstraction for managing container lifecycles, optimizing infrastructure resources, improving agility in the delivery process, and facilitating dependencies management.
Now that a custom Spark scheduler for Kubernetes is available, many AWS customers are asking how to use Amazon Elastic Kubernetes Service (Amazon EKS) for their analytical workloads, especially for their Spark ETL jobs. This post explains the current status of the Kubernetes scheduler for Spark, covers the different use cases for deploying Spark jobs on Amazon EKS, and guides you through the steps to deploy a Spark ETL example job on Amazon EKS. For more info ETL Tesitng Training
Available functionalities in Spark 2.4
Before the native integration of Spark in Kubernetes, developers used Spark standalone deployment. In this configuration, the Spark cluster is long-lived and uses a Kubernetes Replication Controller. Because it’s static, the job parallelism is fixed and concurrency is limited, resulting in a waste of resources.
With Spark 2.3, Kubernetes has become a native Spark resource scheduler. Spark applications interact with the Kubernetes API to configure and provision Kubernetes objects, including Pods and Services for the different Spark components. This simplifies Spark clusters management by relying on Kubernetes’ native features for resiliency, scalability and security.
The Spark Kubernetes scheduler is still experimental. It provides some promising capabilities, while still lacking some others. Spark version 2.4 currently supports:
Spark applications in client and cluster mode.
Launching drivers and executors in Kubernetes Pods with customizable configurations.
Interacting with the Kubernetes API server via TLS authentication.
Mounting Kubernetes secrets in drivers and executors for sensitive information.
Mounting Kubernetes volumes (hostPath, emptyDir, and persistentVolumeClaim).
Exposing the Spark UI via a Kubernetes service.
Integrating with Kubernetes RBAC, enabling the Spark job to run as a serviceAccount.
It does not support:
Driver resiliency. The Spark driver is running in a Kubernetes Pod. In case of a node failure, Kubernetes doesn’t reschedule these Pods to any other node. The Kubernetes restartPolicy only refers to restarting the containers on the same Kubelet (same node). This issue can be mitigated with a Kubernetes Custom Controller monitoring the status of the driver Pod and applying a restart policy at the cluster level.
Dynamic Resource Allocation. Spark applications require an External Shuffle Service for auto-scaling Spark applications to persist shuffle data outside of the Spark executors. For more details ETL Testing Certification
Additionally, for streaming application resiliency, Spark uses a checkpoint directory to store metadata and data, and be able to recover its state. The checkpoint directory needs to be accessible from the Spark drivers and executors. Common approaches is to use HDFS but it is not available on Kubernetes. Spark deployments on Kubernetes can use PersistentVolumes, which survive Pod termination, with readWriteMany access mode to allow concurrent access. Amazon EKS supports Amazon EFS and Amazon FSX Lustre as PersistentVolume classes.
Use cases for Spark jobs on Amazon EKS
Using Amazon EKS for running Spark jobs provides benefits for the following type of use cases:
Workloads with high availability requirements. The Amazon EKS control plane is deployed in multiple availability zones, as can be the Amazon EKS worker nodes.
Multi-tenant environments providing isolation between workloads and optimizing resource consumption. Amazon EKS supports Kubernetes Namespaces, Network Policies, Quotas, Pods Priority, and Preemption.
Development environment using Docker and existing workloads in Kubernetes. Spark on Kubernetes provides a unified approach between big data and already containerized workloads.
Focus on application development without worrying about sizing and configuring clusters. Amazon EKS is fully managed and simplifies the maintenance of clusters including Kubernetes version upgrades and security patches.
Spiky workloads with fast autoscaling response time. Amazon EKS supports Kubernetes Cluster Autoscaler and can provides additional compute capacity in minutes.
Deploying Spark applications on EKS
In this section, I will run a demo to show you the steps to deploy a Spark application on Amazon EKS. The demo application is an ETL job written in Scala that processes New York taxi rides to calculate the most valuable zones for drivers by hour. It reads data from the public NYC Amazon S3 bucket, writes output in another Amazon S3 bucket, and creates a table in the AWS Glue Data Catalog to analyze the results via Amazon Athena. The demo application has the following pre-requisites:
Docker >17.05 on the computer which will be used to build the Docker image.
An existing Amazon S3 bucket name.
An AWS IAM policy with permissions to write to that Amazon S3 bucket.
An Amazon EKS cluster already configured with permissions to create a Kubernetes ServiceAccount with edit ClusterRole and a worker node instance role with the previous AWS IAM policy attached.
If you don’t have an Amazon EKS cluster, you can create one using the EKSCTL tool following the example below (after updating the AWS IAM policy ARN):
eksctl create cluster -f example/eksctl.yaml
In the first step, I am packaging my Spark application in a Docker image. My Dockerfile is a multi-stage image: the first stage is used to compile and build my binary with SBT tool, the second as a Spark base layer, and the last for my final deployable image. Neither SBT nor Apache Spark maintain a Docker base image, so I need to include the necessary files in my layers:
Build the Docker image for the application and push it to my repository:
docker build -t <REPO_NAME>/<IMAGE_NAME>:v1.0 .
docker push <REPO_NAME>/<IMAGE_NAME>:v1.0
Now that I have a package to deploy as a Docker image, I need to prepare the infrastructure for deployment:
Create the Kubernetes service account and the cluster role binding to give Kubernetes edit permissions to the Spark job:
Finally, I need to deploy my Spark application to Amazon EKS. There are several ways to deploy Spark jobs to Kubernetes:
Use the spark-submit command from the server responsible for the deployment. Spark currently only supports Kubernetes authentication through SSL certificates. This method is not compatible with Amazon EKS because it only supports IAM and bearer tokens authentication.
Use a Kubernetes job which will run the spark-submit command from within the Kubernetes cluster and ensure that the job is in a success state. In this approach, spark-submit is run from a Kubernetes Pod and the authentication relies on Kubernetes RBAC which is fully compatible with Amazon EKS.
Use a Kubernetes custom controller (also called a Kubernetes Operator) to manage the Spark job lifecycle based on a declarative approach with Customer Resources Definitions (CRDs). This method is compatible with Amazon EKS and adds some functionalities that aren’t currently supported in the Spark Kubernetes scheduler, like driver resiliency and advanced resource scheduling.
I will use the Kubernetes job method to avoid the additional dependency on a custom controller. For this, I need a Spark base image which contains Spark binaries, including the spark-submit command:
Build the Docker image for Spark and push it to my repository:
Use kubectl to create the job based on the description file, modifying the target Amazon S3 bucket and the Docker repositories to pull the images from:
Use Kubernetes port forwarding to monitor the job via the Spark UI hosted on the Spark driver. First get the driver pod name, then forward its port on localhost and access the UI with your browser pointing to http://localhost:4040 :
After the job has finished I can check the results via the Amazon Athena console by creating the tables, crawling, and querying them:
Add a crawler in the AWS Glue console to crawl the data in the Amazon S3 bucket and create two tables, one for raw rides and one for ride statistics per location:
Enter a crawler name, and click Next.
Select Data stores and click Next.
Select the previously used Amazon S3 bucket and click Next.
Enter a name for the AWS Glue IAM role and click Next.
Select Run on demand and click Next.
Choose the database where you want to add the tables, select Create a single schema for each Amazon S3 path, click Next and then Finish.
Run the crawler and wait for completion.
After selecting the right database in the Amazon Athena console, execute the following queries to preview the raw rides and to see which zone is the most attractive for a taxi driver to pick up:
SELECT * FROM RAW_RIDES LIMIT 100;
SELECT locationid, yellow_avg_minute_rate, yellow_count, pickup_hour FROM "test"."value_rides" WHERE pickup_hour=TIMESTAMP '2018-01-01 5:00:00.000' ORDER BY yellow_avg_minute_rate DESC;
Agent intelligence is an artificial intelligence solution built on the ServiceNow platform. ServiceNow Agent intelligence will help your business to improve productivity and eliminates bottlenecks, which in-turn leads to high customer satisfaction. Explore in detail how ServiceNow agent intelligence works and saves your business costs and time.
AI solutions use machine learning algorithms to deliver predictions based on user input. With the help of machine learning algorithms, AI will understand patterns and predict intelligent outcomes without human intervention. Learn Servicenow Certification
With the help of agent intelligence ServiceNow will categorize, route, and assign work based on the unique characteristics of each customer.
The AI solutions will be prepared by looking at thousands of historical records (i.e., incidents, cases, requests), based on the newly prepared solution the correct categorization, priority, and routing information is applied, decreasing the time it takes to resolve a task.
This automation helps to optimize resources and processes, improve customer satisfaction, and ensure energies are focused on innovation and strategic high-value activities.
Benefits of Agent Intelligence
While working with the manual process, there will be so many errors and bottlenecks will get created. With the help of AI, we can eliminate the bottlenecks and can decrease the error rates and improves productivity results in less downtime. learn more skills from Best Servicenow Online Training
With fewer error rates, the productivity of IT teams will improve gradually. With the automation process end, users will get results in less downtime.
We can achieve great end user/customer satisfaction with AI.
Automating manual tasks will greatly save time and resources.
Roles
No specific roles are required to work with agent intelligence application. Users with the admin role can perform/work with this application.
Prerequisites
Customer needs to purchase this application from ServiceNow to enjoy the agent intelligence application services.
ServiceNow system administrator needs to clone the sub production instance to implement Agent intelligence to test whether this application is running fine or not.
Need to maintain minimum 30 thousand records in sub production instance in which you want to implement the application to prepare/predict accurate solution. For more info Servicenow Training
AI Benchmark Against Peers
AI Preparation
Data Quality: Gather and make sure the data which will be used for AI is as clean as possible.
KPIs: KPI’s are major in ServiceNow. With the help of AI, we can improve our KPIs, average resolution time, customer satisfaction factors-open/re-assignment counts and other KPIs, prior to beginning implementation.
Inputs and Outputs: Agent Intelligence is by default categorizes and assign requests. If you want to provide more information to determine the correct category and assignment group (i.e. Location), make sure to add respective additional inputs to the solution definitions.
Forecast Organizational Change: It is important to estimate the organizational change. Before implementing agent intelligence, we need to create and implement an organizational change plan so as to check if these changes work with the decision makers. Learn from Servicenow Course online
AI Process
Need to select the table to implement AI predictions.
Need to gather min 30 thousand records of the respective table to train the solution.
Can give a maximum of 5 input fields to make predictions.
Only one output field can be selected. The output field is predicted, such as category, priority, or assignment group.
Frequency, which specifies how often to re-train the solution i.e. (daily, weekly, bi-weekly, monthly, etc.)
Once training is completed, we can implement the solutions in the respective instance to make it available for end users.
Tableau was acquired by Salesforce earlier this year for $15.7 billion, but long before that, the company had been working on its fall update, and today it announced several new tools, including a new feature called “Explain Data” that uses AI to get to insight quickly.
“What Explain Data does is it moves users from understanding what happened to why it might have happened by automatically uncovering and explaining what’s going on in your data. So what we’ve done is we’ve embedded a sophisticated statistical engine in Tableau, that when launched automatically analyzes all the data on behalf of the user, and brings up possible explanations of the most relevant factors that are driving a particular data point,” Tableau chief product officer, Francois Ajenstat explained.
He added that what this really means is that it saves users time by automatically doing the analysis for them, and It should help them do better analysis by removing biases and helping them dive deep into the data in an automated fashion.
Ajenstat says this is a major improvement, in that, previously users would have do all of this work manually. “So a human would have to go through every possible combination, and people would find incredible insights, but it was manually driven. Now with this engine, they are able to essentially drive automation to find those insights automatically for the users,” he said. Learn more skills from Tableau Training
He says this has two major advantages. First of all, because it’s AI-driven it can deliver meaningful insight much faster, but also it gives a more rigorous perspective of the data.
In addition, the company announced a new Catalog feature, which provides data bread crumbs with the source of the data, so users can know where the data came from, and whether it’s relevant or trustworthy.
Finally, the company announced a new server management tool that helps companies with broad Tableau deployment across a large organization to manage those deployments in a more centralized way.
All of these features are available starting today for Tableau customers.
Tableau 2019.3 brings automatic data insights to Tableau platform and extends natural language functionality to enable analytics for everyone. Release also provides new capabilities for data cataloging, server management, security and additional data connectors
Tableau Software, the leading analytics platform, today announced the general availability of Explain Data, a new capability built directly in Tableau that enables people to experience the power of advanced statistical analysis with a single click.
With no complex data modeling or data science expertise required, anyone is able to instantly uncover AI-driven insights about their data. Explain Data uses sophisticated statistical algorithms to analyze all available data on behalf of the analyst and automatically explain the most relevant factors driving any given data point.
In doing so, Explain Data brings powerful analytics to more people and helps them discover insights that would be difficult or time-consuming to find. Explain Data is available today at no extra charge as part of Tableau’s latest release, Tableau 2019.3.
“With Explain Data, we’re bringing the power of AI-driven analysis to everyone and making sophisticated statistical analysis more accessible so that, regardless of expertise, anyone can quickly and confidently uncover the “Why?” behind their data,” said Francois Ajenstat, Chief Product Officer at Tableau. “Explain Data will empower people to focus on the insights that matter and accelerate the time to action and business impact.” For more info Tableau Online Course
Explain Data accelerates the analytical process and helps people quickly discover and understand the factors influencing changes within their data – with no set up, data prep or data modeling required.
Traditionally, to understand the cause driving a particular data point or outlier, people must manually determine and validate the potential explanations, a process that can be time consuming and miss plausible answers.
With the release of Explain Data in Tableau 2019.3, they can simply select a data point in a visualization and Tableau will use powerful Bayesian statistical methods to automatically evaluate hundreds of patterns and potential explanations across all the available data in seconds.
Explain Data delivers the most relevant, statistically significant explanations as interactive visualizations which customers can further explore with the full power of Tableau. Get more from Best Online Tableau Training
Explain Data also reduces the risk of error from human bias that can restrict analysis, helping people uncover meaningful insights they may have missed. A person tasked with answering a data question like, “What’s contributing to customer churn?” often must limit their analysis to a set of predetermined hypotheses.
Explain Data evaluates every dimension in the data set automatically, and makes it possible for anyone to uncover hidden insights. Explain Data augments a person’s skills and inherent understanding of the data with advanced statistical techniques that would otherwise be reserved for experts.
“Within JLL, thousands of employees use Tableau on a daily basis to help them see and understand their data. The evolution of self-service analytics is that people are empowered to ask even more questions of their data; going from intrigue to insight.
We anticipate Explain Data will be a game changer that enables guided analytics and helps people to ask the right questions and uncover insights faster,” said Simon Beaumont, Global BI CoE Director, at JLL.
“Explain Data allows anyone, whatever their level of data knowledge, to explore their data and ‘go beyond the number’ to understand not only the what, but also the why – the true definition of democratizing data.” Learn more from tableau Training
Tableau 2019.3 Expands NLP Functionality; Introduces New Connectors and Enhanced Security Dozens of new product features are also included with the upgrade to Tableau 2019.3 including new ways to engage with Tableau’s natural language (NLP) capability, Ask Data.
Now, Ask Data’s natural language functionality can be embedded, such as within a company portal or Intranet page, so that more people are encouraged to use the capability as part of their daily role, asking data questions in plain language like, “What were my sales in Seattle last month?”
With the ability to embed Ask Data, organizations will enable even more people to interact with data, empowering employees with a visualization that they can continue to refine and explore using Tableau’s full analytics capabilities.
For added layers of security, Tableau Server customers can now encrypt their data extracts at rest, ensuring all extracts published and stored via Tableau Server are encrypted.
Tableau also continues to add new data connectors to the platform with every release. With 2019.3, customers using Spark for machine learning and data science can now benefit from a native data connector to Databricks. Additionally, all Tableau products are now available in localized versions for Italian. Learn Best Tableau Online Courses
Alongside the release of Tableau 2019.3, today, Tableau announced the launch of Tableau Catalog, a new set of cataloging capabilities now included in the Data Management Add-On that provide a holistic view of all the data used in Tableau for improved visibility and enhanced data discovery.
Additionally, to offer customers more control in how they manage and scale business critical deployments, Tableau released a new offering to address the unique security, manageability and scalability needs of enterprise customers, the Tableau Server Management Add-On.
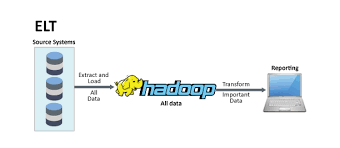
Mention ETL (Extract, Transform and Load) and eyes glaze over. The thought goes: “That stuff is old and meant for clunky enterprise data warehouses. What does it have to do with my Internet/Web/ecommerce application?”
Quite a lot, actually. ETL did originate in enterprise IT where data from online databases is Extracted, then Transformed to normalize it and finally Loaded into enterprise data warehouses for analysis.
Although Internet companies feel they have no use for expensive, proprietary data warehouses, the fact of the matter is that ETL is still a requirement and so is some kind of a data warehouse. The logic is simple: one doesn’t run business reports on the database powering the online application. Get more from ETL Training
An ETL Example
Consider the classic example of key transformation. The application database uses a customer_id to index into the customer table, while the CRM system has the same customer referenced differently.
The business analyst wants to analyze how customers are using the product and thus, the data warehouse needs a distinct way to refer to customers i.e. the keys need to be transformed and mapped to a new key in the DW.
Even if there is a single source system, it is still a good idea to do such transformations to isolate the warehouse from the online database. In addition to such basic transformations, data is also often enriched (as for example using geocodes) to create the target customer record in the warehouse.
There is no getting away from it: ETL is a requirement whether you are the hottest social media company or a 50-year-old bank.
Why Hadoop?
All right. We need ETL. But what has Hadoop got do with it?
Turns out that Hadoop is an ideal platform to run ETL. You can feed the results into a traditional data warehouse, or better yet, simply use Hadoop itself as your warehouse. Two for the price of one! And ingesting data from all sources into a centralized Hadoop repository is future proof: as your business scales and the data grows rapidly, the Hadoop infrastructure can scale easily.
The Hadoop platform has tools that can extract the data from the source systems, whether they are log files, machine data or online databases and load them to Hadoop in record time.
It is possible to do transformations on the fly as well, although more elaborate processing is better done after the data is loaded into Hadoop. Programming and scripting frameworks allow complex ETL jobs to be deployed and executed in a distributed manner.
Rapid improvements in interactive SQL tools make Hadoop an ideal choice for a low cost data warehouse. Learn more from ETL Testing Certification
Got it. What needs to be done to get this all to work? Read on to find out.
ETL Process in Hadoop
Here are the typical steps to setup Hadoop for ETL:
Set up a Hadoop cluster,
Connect data sources,
Define the metadata,
Create the ETL jobs,
Create the workflow.
Set Up a Hadoop Cluster
This step can be really simple or quite difficult depending on where you want the cluster to be. On the public cloud, you can create a Hadoop cluster with just a few clicks using Amazon EMR, Rackspace CBD, or other cloud Hadoop offerings. If the data sources are already on the same public cloud, then this is obviously the no-brainer solution.
If however your data sources happen to be in an in-house data center, there are a couple of things to take into consideration:
Can the data be moved to the cloud? Legal, security, privacy and cost considerations apply.
Can test data be used for development?
If the answer is No to both questions, then a cluster will need to be provisioned in the data center. Go befriend your IT/OPS guy right away.
Connect Data Sources
The Hadoop eco-system includes several technologies such as Apache Flume and Apache Sqoop to connect various data sources such as log files, machine data and RDBMS.
Depending on the amount of data and the rate of new data generation, a data ingestion architecture and topology must be planned. Start small and iterate just like any other development project. The goal is to move the data into Hadoop at a frequency that meets analytics requirements.
Define the Metadata
Hadoop is a “schema-on-read” platform and there is no need to create a schema before loading data as databases typically require. That does not mean one can throw in any kind of data and expect some magic to happen.
It is still important to clearly define the semantics and structure of data (the “metadata”) that will be used for analytics purposes. This definition will then help in the next step of data transformation.
Going back to our example of the customer ID, define how exactly this ID will be stored in the warehouse. Is it a 10 digit numeric key that will be generated by some algorithm or is it simply appending a four digit sequence number to an existing ID?
Many Hadoop projects are begun without any clear definition of metadata. Just like ETL, the term “Metadata Management” is considered old school and meant for traditional enterprise IT, not for our modern data architecture.
But in reality, metadata is crucial for the success of Hadoop as a data warehouse. With a clear design and documentation, there is no ambiguity in what a particular field means or how it was generated. Investing up front in getting this right will save a lot of angst later on.
With the metadata defined, this can be easily transposed to Hadoop using Apache HCatalog, a technology provides a relational table view of data in Hadoop. HCatalog also allows this view to be shared by different type of ETL jobs, Pig, Hive, or MapReduce.
Create the ETL Jobs
We can finally focus on the process of transforming the various sources of data. Here again, multiple technologies exist: MapReduce, Cascading and Pig are some of the most common used frameworks for developing ETL jobs.
Which technology to use and how to create the jobs really depends on the data set and what transformations are needed. Many organizations use a combination of Pig and MapReduce while others use Cascading exclusively.
Learn about all the different ways transform jobs are done and the strengths and weaknesses of the various technologies.
A word of caution – engineers experienced in enterprise data management may be prone to aggressive data cleansing and transformation. They want order and the data to confirm to pre-defined schemas.
However, the whole notion of big data is that it can be unstructured. Machine and sensor data are likely to be noisy, and social media and other data may not fit into neat buckets.
Too much cleansing can get rid of the very insights that big data promises. A thoughtful approach is required to get the most value from your data.
Create the Workflow
Data cleansing and transformations are easier done when multiple jobs cascade into a workflow, each performing a specific task. Often data mappings/transformations need to be executed in a specific order and/or there may be dependencies to check.
These dependencies and sequences are captured in workflows – parallel flows allow parallel execution that can speed up the ETL process. Finally the entire workflow needs to be scheduled. They may have to run weekly, nightly, or perhaps even hourly.
Although technologies such as Oozie provide some workflow management, it is typically insufficient. Many organizations create their own workflow management tools.
This can be a complex process as it is important to take care of failure scenarios and restart the workflow appropriately.
A smooth workflow will result in the source data being ingested and transformed based on the metadata definition and stored in Hadoop. At this point, the data is ready for analysis.
And you guessed it! There are many different ways to do that with Hadoop; Hive, Impala and Lingual provide SQL-on-Hadoop functionality while several commercial BI tools can connect to Hadoop to explore the data visually and generate reports.
Celebrate!
We are finally done! We have created a data warehouse in Hadoop. Although this seems complicated (depending on the data and requirements), almost all of the technologies are open-source and available for free.
Tools are now emerging that help automate some part of this process. If your organization does not have the expertise, it may be a good idea to engage outside services to get started on this new architecture and technologies, while hiring/training your own staff.
Data warehouses are a requirement even for Web/Internet companies. Data cleansing, data transformation, ETL, metadata are all terms that are still relevant for new data architectures.
But they don’t need to be created using proprietary, expensive products. Leveraging big data technologies such as Hadoop will ensure your data architecture stands the test of time (at least until the next big wave!)