Hadoop’s significance in data warehousing is progressing rapidly as a transitory platform for extract, transform, and load (ETL) processing. Mention about ETL and eyes glaze over Hadoop as a logical platform for data preparation and transformation as it allows them to manage huge volume, variety and velocity of data flawlessly.
Hadoop is extensively talked about as the best platform for ETL because it is considered as an all-purpose staging area and landing zone for enterprise big data.
To understand the significance of big data and hadoop for ETL professionals read this article to endorse the awareness on why is this the best time to pursue a career in big data hadoop for all data warehousing and ETL professionals.
The spurt of internet users and the adoption of technology by all the conceivable industries through the past two decades began generating data in exponentially expanding volumes. Get more from ETL Testing Online Training
As the data kept growing, owners realized a need to analyze it and thus originated an entirely new domain of Data Warehousing. That laid the foundation for an entirely new domain of ETL (acronym for Extract Transform Load) – a field which continues to dominate the data warehousing to this date.
Data is the foundation of any Information Technology (IT) system and as long as we are prepared to manipulate and consume it, we will keep adding value to the organization. The modern technological ecosystem is run and managed by interconnected systems that can read, copy, aggregate, transform and re – load data from one another. While the initial era of ETL ignited enough sparks and got everyone to sit up, take notice and applaud its capabilities, its usability in the era of Big Data is increasingly coming under the scanner as the CIOs start taking note of its limitations.
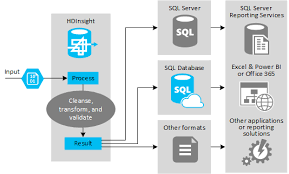
Hadoop for ETL platform
Extract, transform and load processes form the backbone of all the data warehousing tools. This has been the way to parse through huge volumes and data and prepare it for analysis. That notion has been challenged of late, with the rise of Hadoop.
Industry experts place a great emphasis on individuals to learn Hadoop. Josh Rogers, President of Syncsort, global business operations and sales lead says, “Data integration and more specifically, Extraction, Transformation and Loading (ETL), represents a natural application of Hadoop and a precedent to achieving the ultimate promise of Big Data – new insights. But perhaps most importantly at this point in the adoption curve, it represents an excellent starting point for leveraging Hadoop to tackle Big Data challenges.” For more details ETL Testing Training
Though industry experts are still divided over the advantages and disadvantages of one over the other, we take a look at the top five reasons why ETL professionals should learn Hadoop.
Wider Career Path
The ETL vs. Hadoop debate is gathering momentum by the day and there is no clear cut winner in sight in the near future. They both offer their own set of advantages and disadvantages. There is no generalized solution and the preference of one over the other is often a matter of choice and both the approaches are holding their ground firmly.
If you encounter Big Data on a regular basis, the limitations of the traditional ETL tools in terms of storage, efficiency and cost is likely to force you to learn Hadoop. Thus, why not take the lead and prepare yourself to tackle any situation in the future? As things stand currently, both the technologies are here to stay in the near future. There can be requirement specific situations where one is preferred over the other and at times both would be required to work in sync to achieve optimal results.
Handle Big Data Efficiently
The emergence of needs and tools of ETL proceeded the Big Data era. As data volumes continued to grow in the traditional ETL systems, it required a proportional increase in the people, skills, software and resources. With the passage of time the huge volume of data began pressurizing the resources and the performance parameters started taking a dip. A number of bottlenecks surfaced in the traditionally smooth ETL processes. As ETL involves reading data from one system, copying and transferring it over the network and writing in another system, the growing volumes of data started adversely affecting the performance parameters.
Systems that contain the data are often not the ones that consume it and Hadoop is changing that concept. It is a data hub in enterprise architecture and presents an inexpensive, extreme performance storage environment to transform and consume data without the need to migrate large chunks of it over the network systems.
At times, all ETL does is to just extract data from one system, perform minor aggregation functions and load it into another system. A majority of it only causes systematic bottlenecks and often does not add any value and for an activity that is essentially non – value add, the costs and time spent is becoming unmanageable.
To get in-depth knowledge, enroll for a live free demo on ETL Testing Certification
